Reading time - 7 mins
1. ML Picks of the Week
A weekly dose of ML tools, concepts & interview prep. All in under 1 minute.
2. Technical ML Section
Learn how to choose between LASSO and Ridge Regression Models.
3. Career ML Section
Learn 3 ML career tips of the month that can help in yearly (1-4 y.e.) career
1. ML Picks of the Week
🥇ML Tool
Python Library DARTS
DARTS makes time series forecasting simple, flexible, and production-ready — all in Python.
It provides a unified API for classical models (ARIMA, Exponential Smoothing) and modern deep learning models (RNNs, TCN, Transformers).
DARTS is especially powerful for:
-
Quickly prototyping with multiple forecasting models
-
Handling multivariate and probabilistic forecasts
-
Backtesting, ensembling, and model comparison — all out of the box
If you’re still building time series models from scratch or mixing different libraries, start using Darts to streamline your forecasting workflow.
📈 ML Concept
SHAP Values
SHAP (SHapley Additive exPlanations) is a powerful method to interpret ML model predictions by assigning each feature an importance value.
-
Based on game theory, they show how much each feature contributed to a prediction
-
SHAP works with any ML model: tree-based, linear, neural networks, etc.
-
SHAP helps explain individual predictions and overall model behavior
SHAP is especially useful for debugging, building trust with stakeholders, and meeting model transparency requirements.
Read a crystal clear breakdown on how SHAP works HERE.
🤔 ML Interview Question
What is the major difference between Gradient Boosting & Random Forest?
Both are ensemble learning methods that combine decision trees, but they differ in how they build and combine those trees.
Random Forest builds many trees independently using random subsets of data and features.
Gradient Boosting builds trees sequentially, where each new tree tries to correct the errors made by the previous trees.
Key differences:
-
Random Forest relies on averaging many uncorrelated trees to improve stability
-
Gradient Boosting creates a strong learner by combining many weak learners in a targeted way
2. Technical ML Section
How to choose between Ridge and LASSO?
(Read a more detailed article here)
You’re building a regression model & you know it might overfit.
So you decide to add regularization. But now you're stuck:
L1 (LASSO) or L2 (Ridge)?
- They sound similar.
- They both penalize model complexity.
- They both help prevent overfitting
In this newsletter, you'll learn:
- What exactly is the difference between LASSO and Ridge
- Which one to use (and when not to)
- A quick cheat sheet to remember it all
Note: LASSO or Ridge are not constrained to linear models.
But for simplicity, in this newsletter, we will consider the linear form only.
1️⃣ What is LASSO?
Imagine that we want to fit (i.e., find weights) a linear model of the following form:
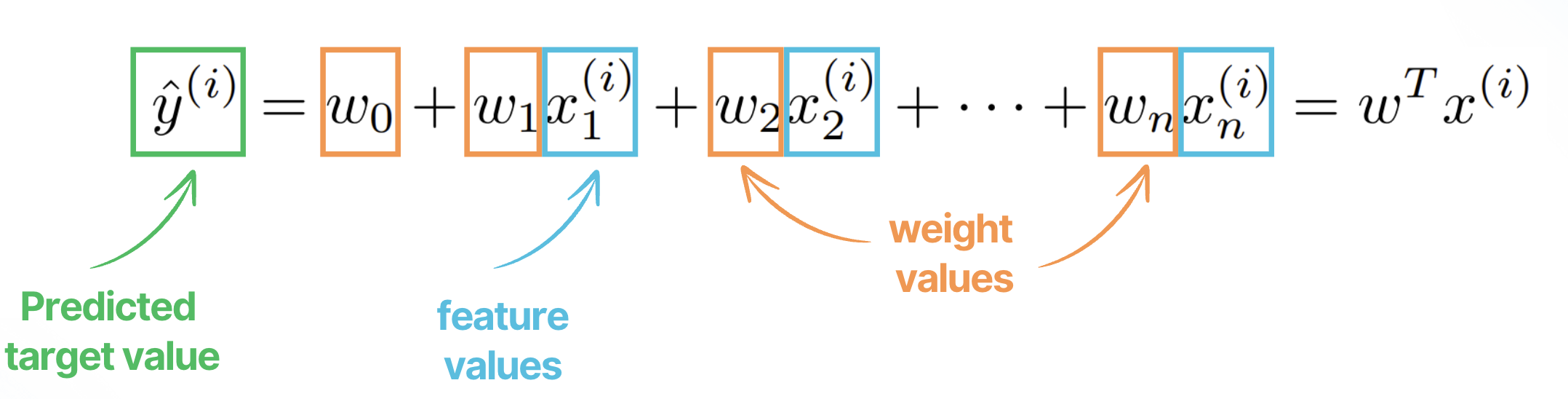
To fit the model and find the weights, LASSO minimizes the following objective function:

We see that, in addition to the MSE error, the objective function has a penalty term expressed as the sum of the weights' absolute values.
When the optimization problem is formed, this penalty term creates a constrained region in the form of a diamond shape in the optimization space.
Due to the constrained shape nature, LASSO naturally drives part of the weights towards zero, see the image below.
(Read a more detailed description in this article)
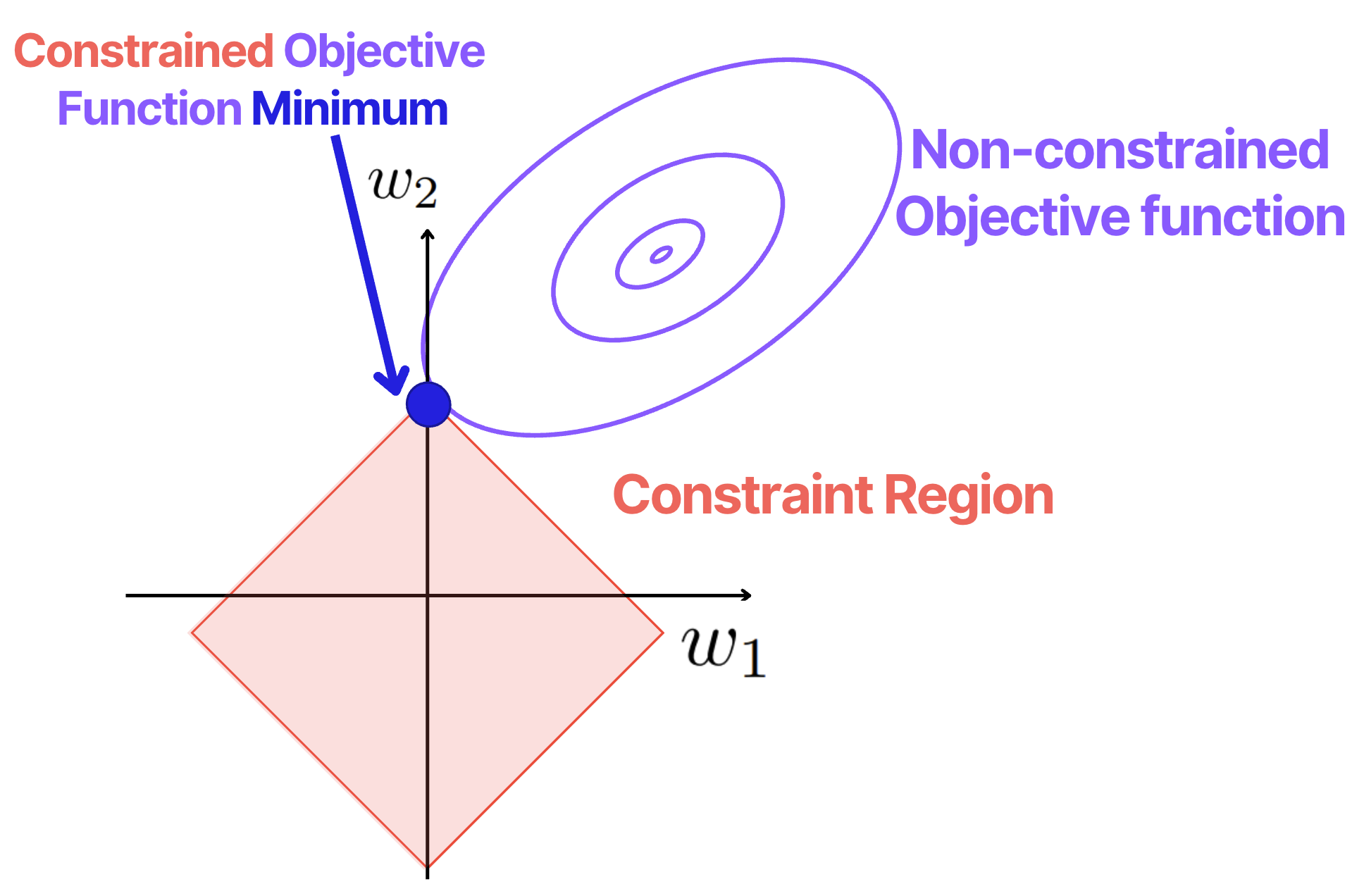
So, often after the LASSO model is fitted, some of the feature coefficients (weights) can become exactly zeros.
As such, the direct result of LASSO model fitting is feature selection!
2️⃣ What is Ridge?
Similar to LASSO, Ridge minimizes the constrained objective function, however, this function has a different form:

While the absolute weight values created a diamond shape for LASSO, for Ridge it creates a circle, see the image below.
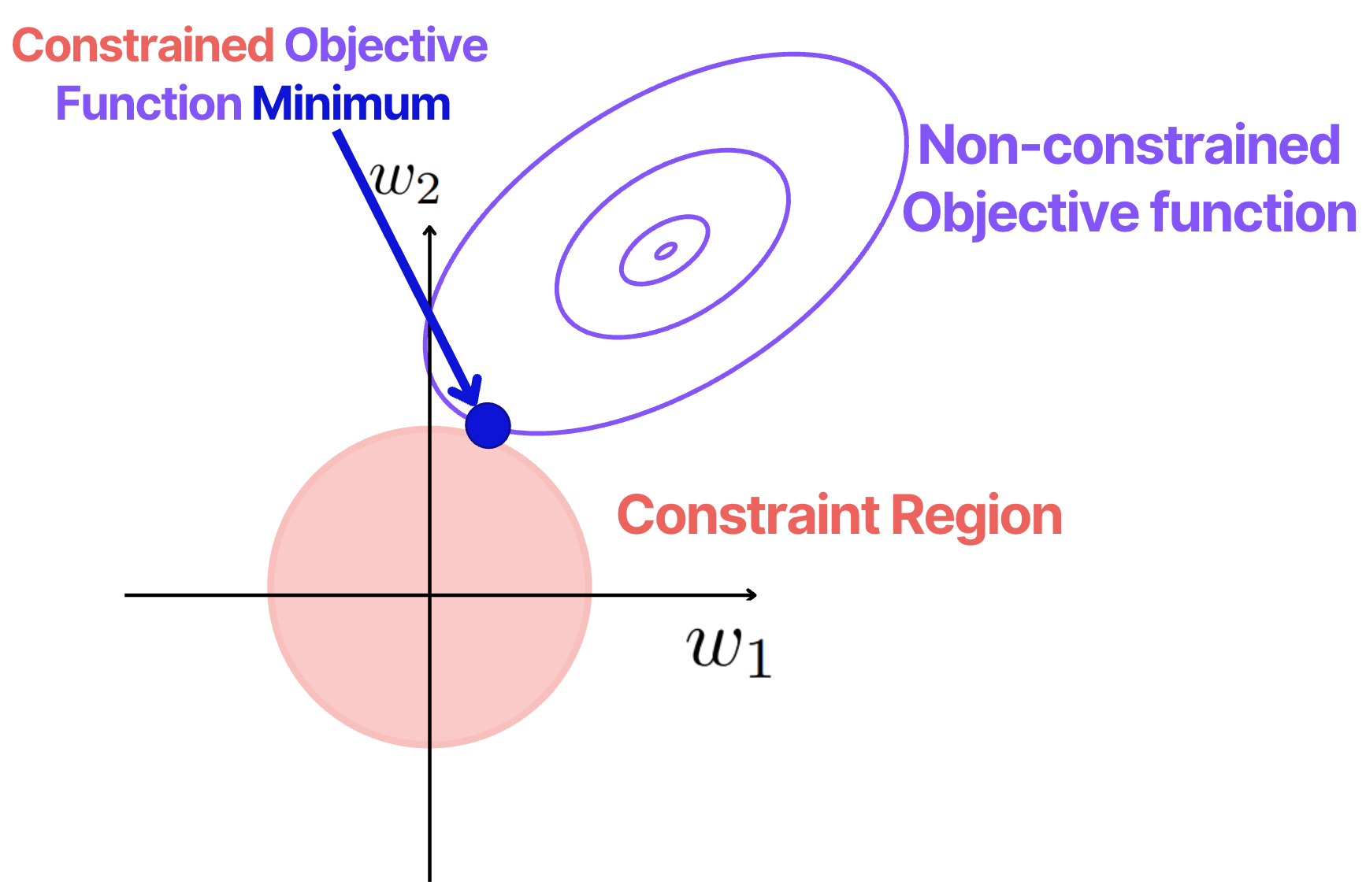
Which difference does it make compared to LASSO?
In this case, the weights also get smaller compared to the case with the unconstrained objective. However, they are NOT forced to become zero!
3️⃣ So, what is the main difference?
As we see above, the main difference between LASSO and Ridge is the fact that LASSO naturally drives part of the weights towards zero. This naturally creates the process of feature selection.
Ridge, on the other hand, does not drive weights to zero while it drives them to become small.
Now, 3 questions arise:
Q1: Can Ridge give you zero weights?
Answer: Yes, sure!
Q2: Does LASSO create more zero weights than Ridge?
Answer: Yes, and this is exactly the main difference between them!
Q3: When to use what?
Answer: See below!
4️⃣ When to use LASSO vs Ridge?
Here’s a practical decision guide based on the behavior of both methods:
✅ Use LASSO when:
-
You expect that only a few features are truly relevant
-
You want automatic feature selection
-
You’re working with high-dimensional data
📌 Good for: sparse models, simplifying features, quick filtering
❌ Avoid LASSO when:
-
You have many collinear (correlated) features
LASSO tends to pick one and ignore the rest, and that choice can change with small shifts in the data
✅ Use Ridge when:
-
You believe most features are relevant, even if weakly.
-
Your dataset includes many correlated features.
Ridge distributes the weight across correlated predictors instead of picking one. That makes it more stable and more robust.
📌 Example use cases: regularizing large models, preventing multicollinearity issues.
❌ Avoid Ridge when:
-
You believe some features are irrelevant and want the model to ignore them.
🔥 Cheat sheet:

2. ML Career Section
3 ML Career Tips of the Month
These are the ML Career tips I wish I knew when I was starting my career.
These tips are relevant to all Data Scientists and Machine Learning Engineers with up to 4 years of experience.
The tips are:
1. Focus on end-to-end ML skills
2. Learn 1-2 ML and business domains deeply
3. Join a good team & team lead, not a company brand
Why are these tips important?
-> Focusing on end-to-end ML skills will help to:
- See the bigger picture when building models
- Learn a lot more than just data analysis
- Get skills that are in high demand.
-> Focusing on 1-2 ML and business domains will give real expertise for which companies pay more, not less.
Why not learn many ML domains?
My take: "Learning everything = knowing nothing". ALWAYS TRUE.
-> Having a good team and team lead over company brands matters because:
- You learn from people, not company names
- Big corporations slowly adapt to new technologies
- Knowledge is worth a lot more than a company brand
Hope this helps in your ML Career Journey!
Related articles
That is it for this week!
If you haven’t yet, follow me on LinkedIn where I share Technical and Career ML content every day!
Whenever you're ready, there are 3 ways I can help you:
1. ML Career 1:1 Session
I’ll address your personal request & create a strategic plan with the next steps to grow your ML career.
2. Full CV & LinkedIn Upgrade (all done for you)
I review your experience, clarify all the details, and create:
- Upgraded ready-to-use CV (Doc format)
- Optimized LinkedIn Profile (About, Headline, Banner and Experience Sections)
3. CV Review Session
I review and show major drawbacks of your CV & provide concrete examples on how to fix them. I also give you a ready CV template to make you stand out.
Join Maistermind for 1 weekly piece with 2 ML guides:
1. Technical ML tutorial or skill learning guide
2. Tips list to grow ML career, LinkedIn, income