Reading time - 4 mins
1. Technical ML Section
Breakdown of the Data Drift and why it’s important to monitor.
The full article is HERE (reading time - 6 mins).
2. Career ML Section
3 tips to efficiently tailor your CV to the job opening
1. Technical ML Section:
(For a more detailed discussion, read the full blog article!)
When a machine learning model is deployed, it starts encountering real-world data. Ideally, this data remains similar to what the model was trained on.
However, in most cases, the data changes over time. This phenomenon is known as Data Drift.
What is Data Drift?
Data drift happens when the statistical properties of input data (features) change—for example, shifts in the mean, median, or standard deviation.
Mathematically, this is often described as a change in P(X), the probability distribution of the input data.
Real-World Data Drift Example
In the full topic article, we discuss a coffee roasting plant example where an ML model predicts outlet coffee humidity based on bean size and roasting temperature.
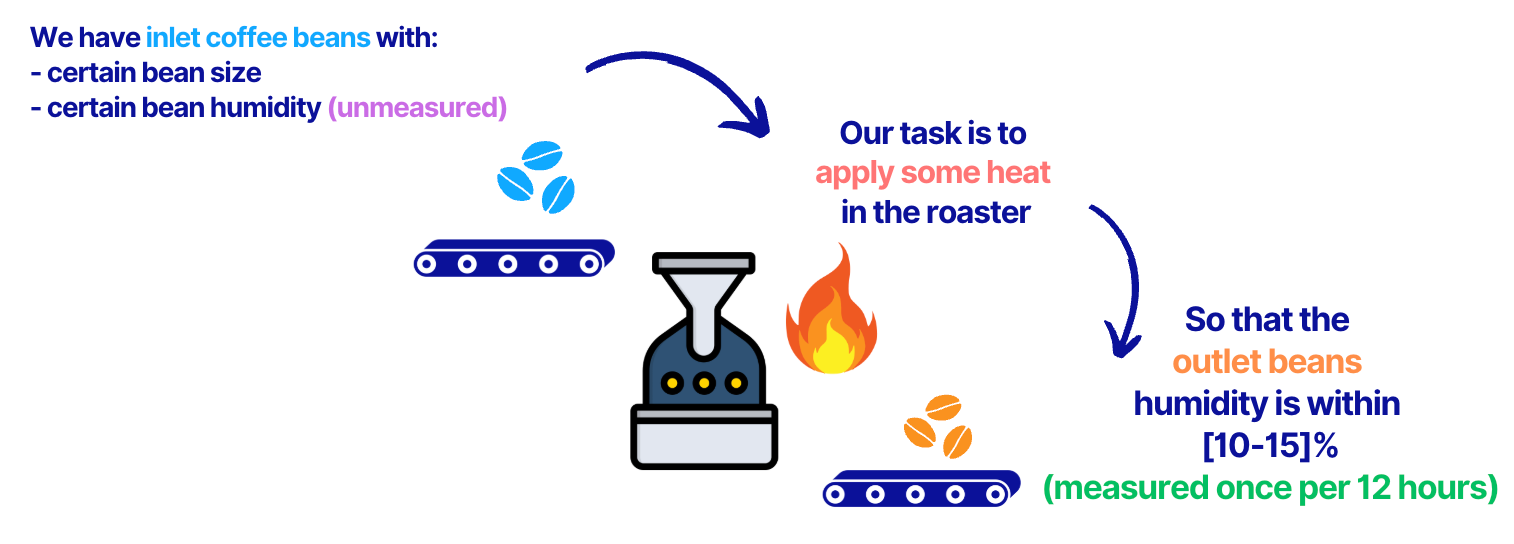
If the coffee supplier changes (e.g., beans come from Colombia instead of Brazil), the inlet bean size might shift - causing data drift.
The model is still the same, but its inputs no longer match the original data, potentially reducing accuracy.
Why Monitor Data Drift?
(for detailed scenarios discussion, see the full article)
Scenario 1: Target labels are rarely available
-
Many production models don’t get continuous feedback (i.e., labeled data).
-
In this case, without data drift monitoring, model errors may go undetected for a long time.
Data drift tracking helps estimate performance in real time without labeled data continuously available.
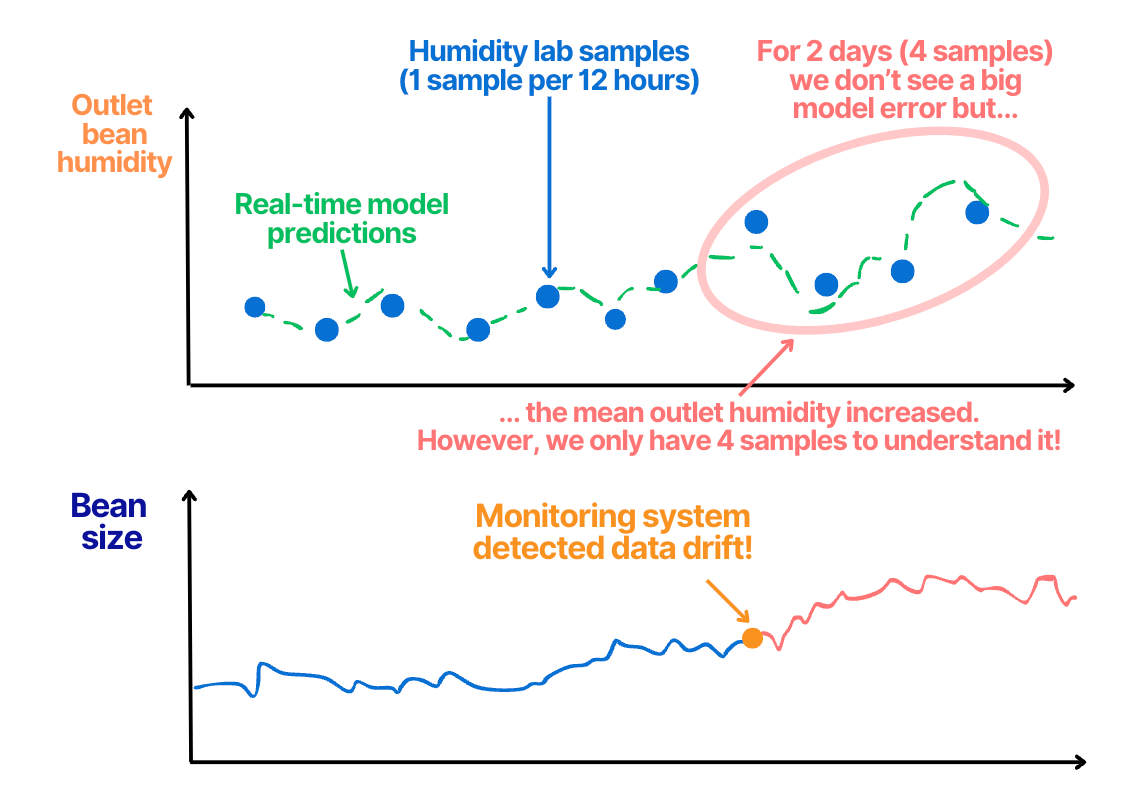
Scenario 2: Understanding the root cause of model performance drops
-
If the model performance drops, data drift detection helps understand if this drop is caused by the change of the input data or not.
-
This will trigger the decision making process about the proper model usage and re-training.
Scenario 3: Avoiding Misinterpretation of Model Errors
In case the model error increases but the data drift does NOT happen, the problem might not be the model—it could be because of incorrect ground-truth labels. Data Drift monitoring might help to identify that.
Takeaways
Data Drift is a shift in statistical properties of the model input data (features) over time, affecting model performance.
Continuous data drift monitoring is an important part of ML systems because:
-
It helps to estimate the model performance when true target values are rarely available
-
It helps to understand the root cause of a bad model performance
In the next issues, we will closely look at different ways to monitor and detect data drift.
2. Career ML Section
2 tips to efficiently tailor your CV to the job opening
✅ Tip 1: Make your summary section as bullet points and put job opening keywords there
Example below shows a tailored Summary section for a job opening focused on ML solutions for industrial processes.

✅ Tip 2: Create Key Skills Section and skills specific to the job opening
Summary, Key Skills and the Top 1 Experience Section position is what usually HRs review.
Put Key Skills section right after summary and add the skills that are specific to the job opening as in the example below.
PRO Tip: Focus on higher level / business oriented skills, not just sklearn or PyTorch.

That is it for this week!
If you haven’t yet, follow me on LinkedIn where I share Technical and Career ML content every day!
Join THE mAIstermind for 1 weekly piece with 2 ML guides:
1. Technical ML tutorial or skill learning guide
2. Tips list to grow ML career, LinkedIn, income