Machine Learning Roadmap. From Zero to Advanced.
Mar 04, 2025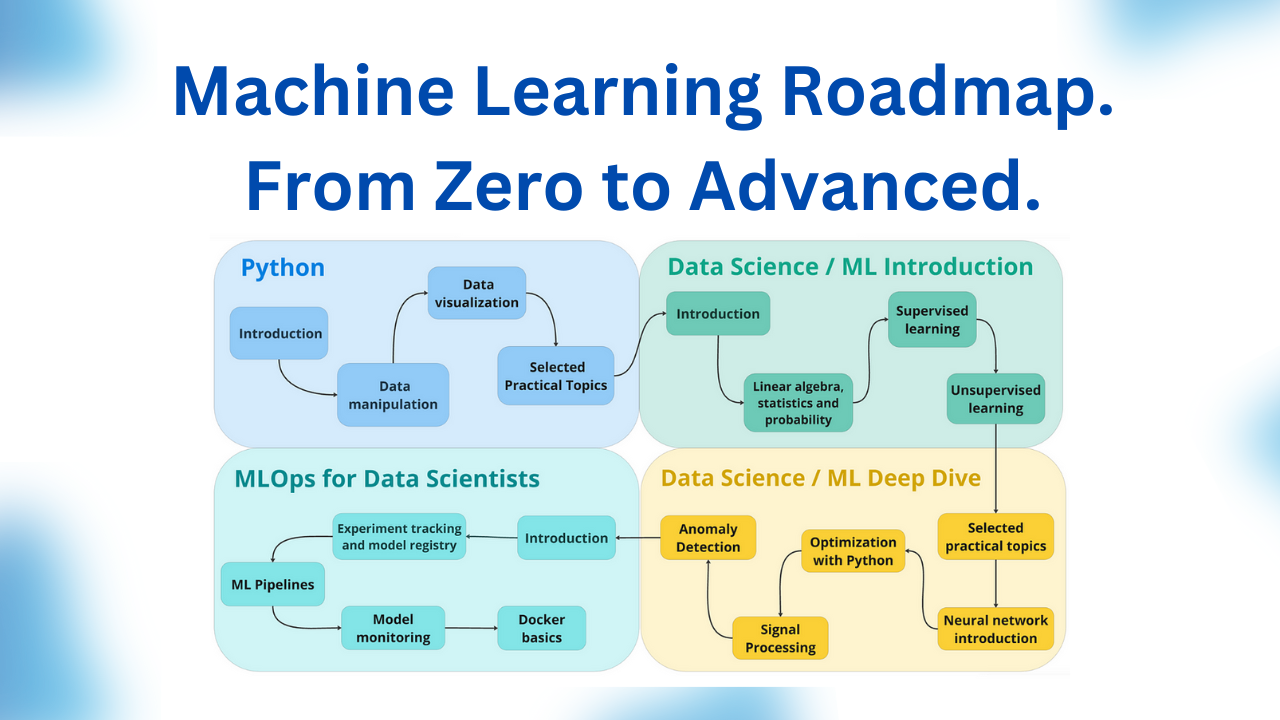
📌 Download the PDF Version of the Roadmap

📌 Before we start…
- If you like the roadmap, you will also like my weekly newsletter! SUBSCRIBE HERE!
- Every day, I also post Machine Learning Content on LinkedIn, follow me!
⭐ Intro
Getting into Machine Learning and Data Science without a clear Machine Learning Roadmap can feel overwhelming.
When I started my ML journey in 2017, there were not much of structured resources. Now, the problem is the opposite — there’s too much material, making it hard to know where to begin.
I’ve seen this struggle firsthand, mentoring 70+ aspiring Data Scientists who all asked the same question: “Where should I start?” This roadmap is the answer to this question.
With 7+ years in the ML field, after leading 4 teams and building 8 end-to-end Machine Learning solutions, I’ve learned what truly matters for a successful Data Science career.
This guide provides a structured, step-by-step path to go from beginner to Middle/Senior Data Scientist — with insights even useful for Lead roles.
🟢 Roadmap Alternative Views
- You can download this ML Roadmap as a PDF Document HERE.
- You can view this ML Roadmap as a GitHub Repo HERE (support us with a STAR!)
- This is a Medium Article
👉 This roadmap is for:
- Data Science beginners who are looking for a practical step-by-step guide.
- Data Scientists who aim to level up skills for a job change or promotion.
- Data Scientists who are looking to refresh their knowledge and prepare for interviews.
- Data Scientists who want to level up skills in a specific domain, e.g. Optimization.
📚 Roadmap Overview
Ok, enough talking. This is the roadmap overview. We will be breaking down each part in detail below.
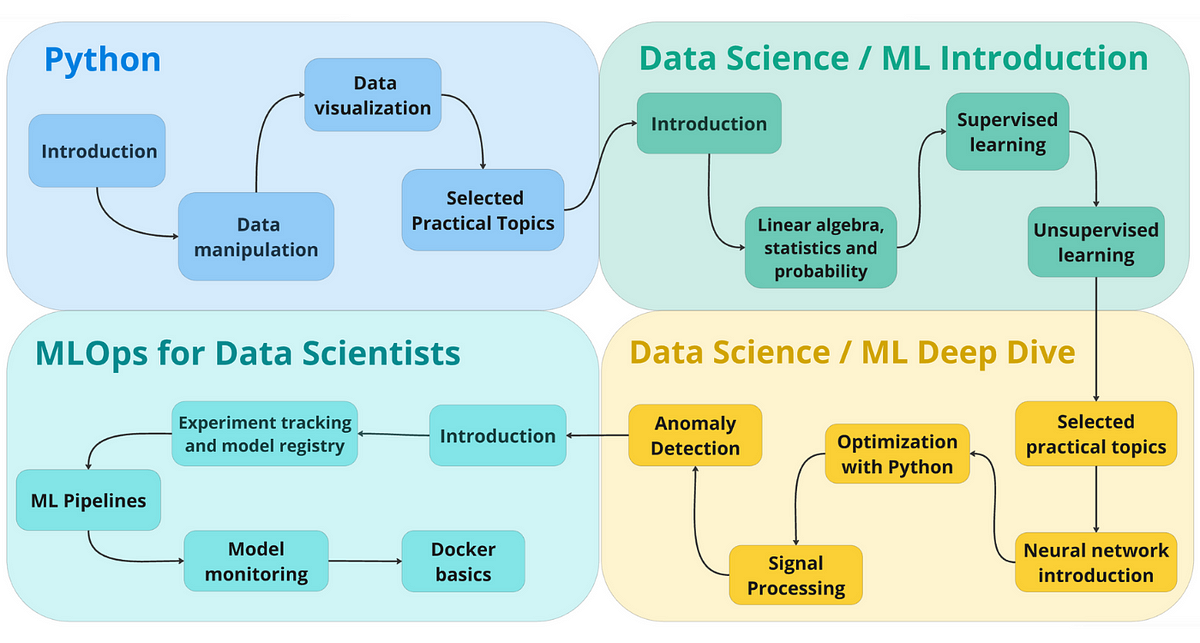
Machine Learning Roadmap Overview
You will learn things step-by-step, slowly increasing the importance and the difficulty of the topics.
I recommend that you complete the first 2 modules (Python and ML intro) and slowly start building your own small project. Then grow this project as you go through the ML deep dive and MLOps modules.
Now, let’s start.
1. Python
Life is too short, learn Python. Forget R or S or T or whatever other programming language letters you see.
1.1 Introduction
Here, I propose 2 versions — free and paid. If you ask me, I would go for the paid version because I think those courses are a bit better structured and easier to start with.
Paid version:
Course 1: Basic Python from CodeAcademy
Course 2: Python Programming Skill Track from DataCamp
Free version:
Course 1: Course from futurecoder.io
This course is similar to the CodeAcademy course from the paid version and even has a similar online programming editor. This is a great start for a complete beginner.
Course 2: Course from Dave Gray
Out of tens of free video courses, I found this one to be well-explained with clear language.
Course 3: Mini-project course from freeCodeCamp
1.2 Data manipulation (Pandas & Numpy)
Now, that you are familiar with Python, we can go to what data scientists use it for.
- Step 1: Kaggle Pandas course with exercises
This is a great start with Pandas. Go cell by cell of the notebooks and I HIGHLY RECOMMEND (in fact, I insist), complete exercises. - Step 2: Data manipulation topic in awesome mlcourse.ai by Yury Kashnitsky and Co.
- Step 3: Data manipulation with Numpy
- Step 4 (optional): Pandas exercises repo by Guilherme Samora
1.3 Data visualization
Data visualization is a critical part of data scientist work, so you must know how to make good plots to tell a story.
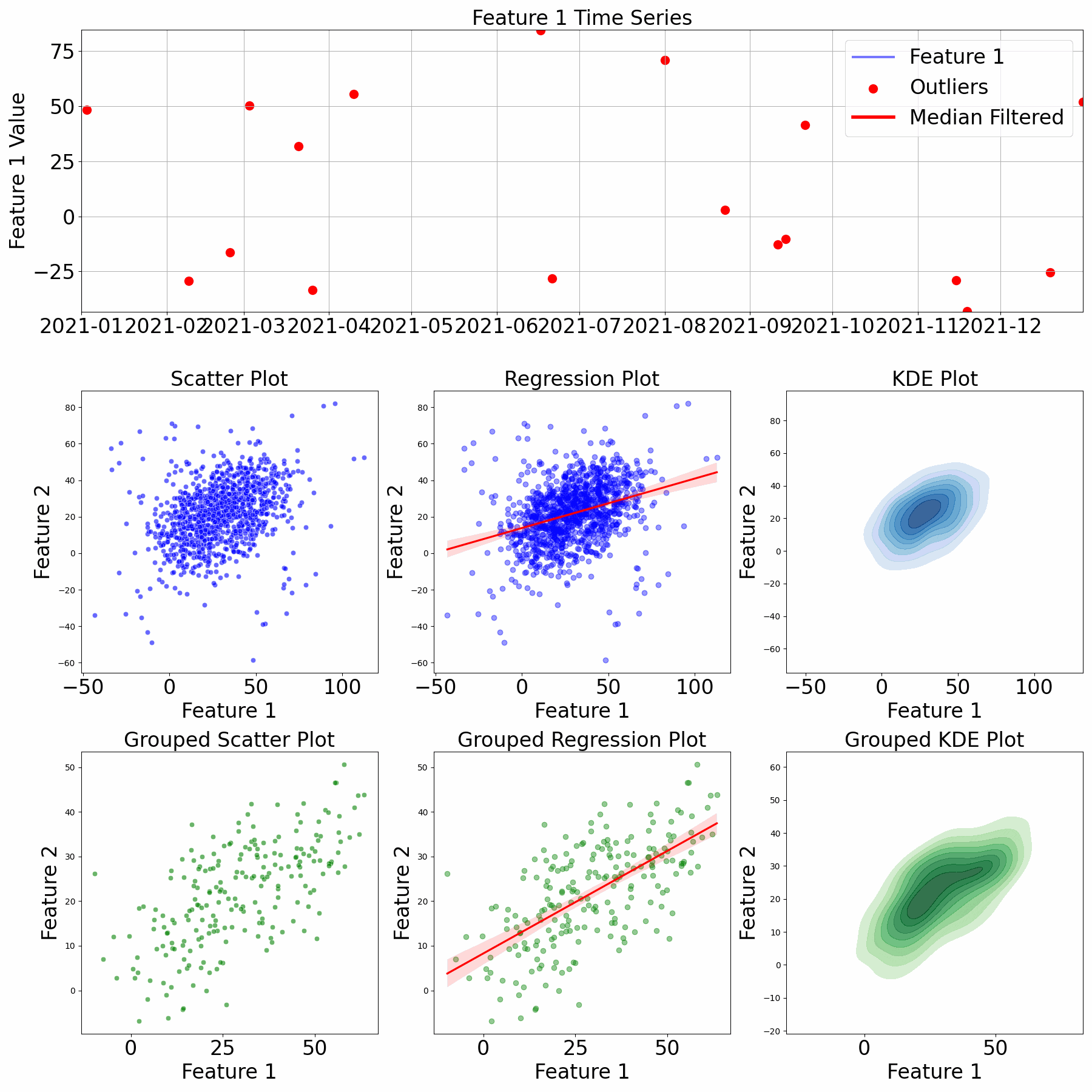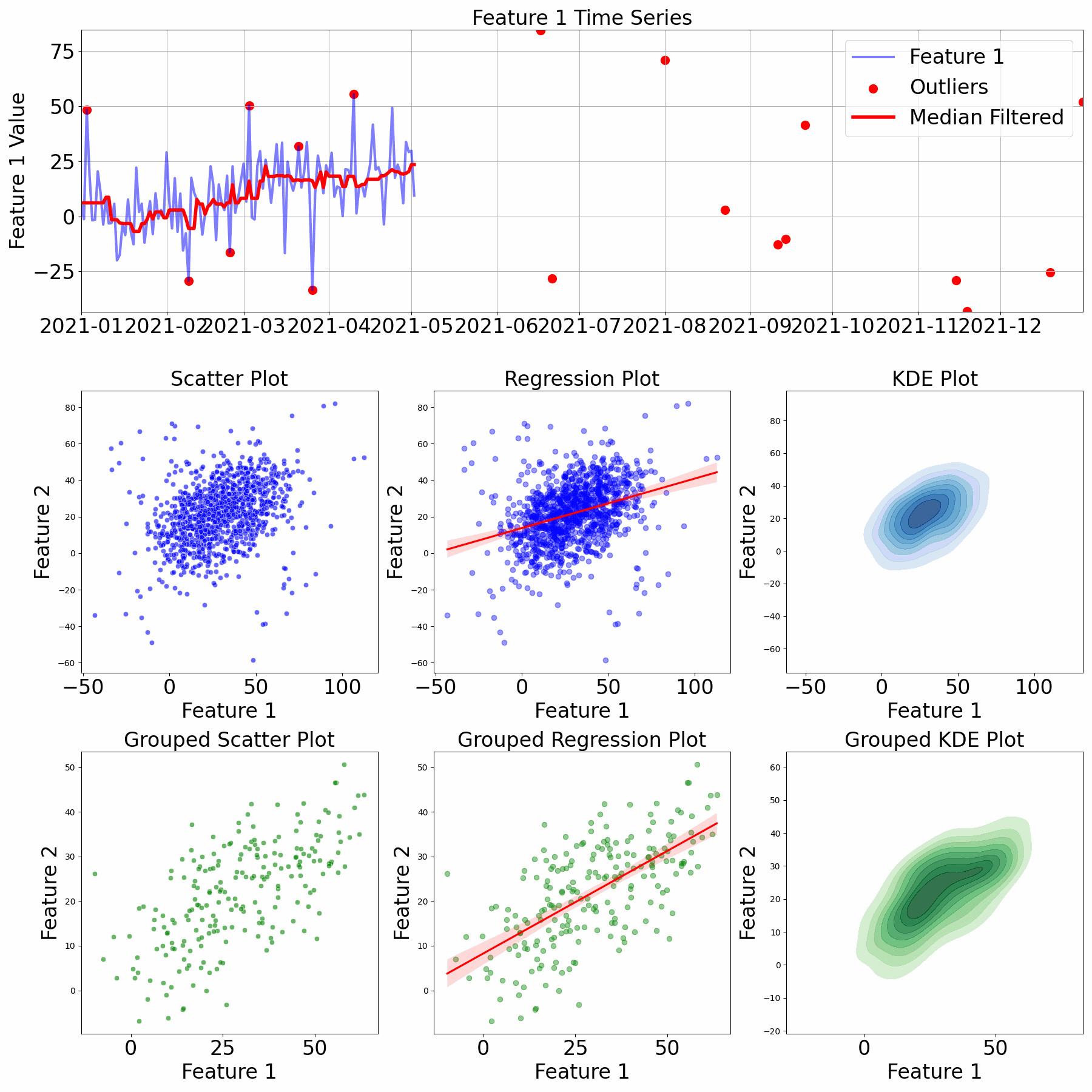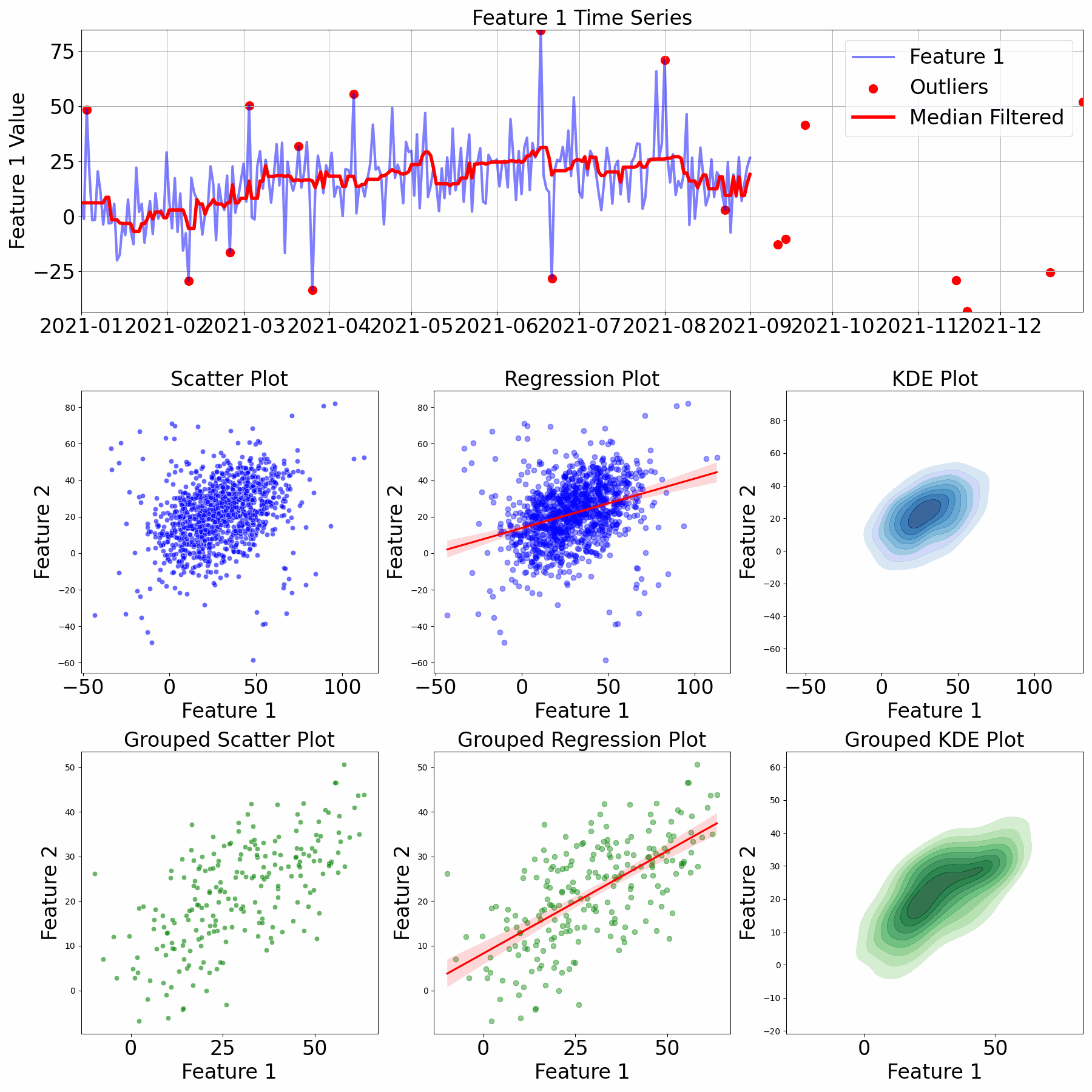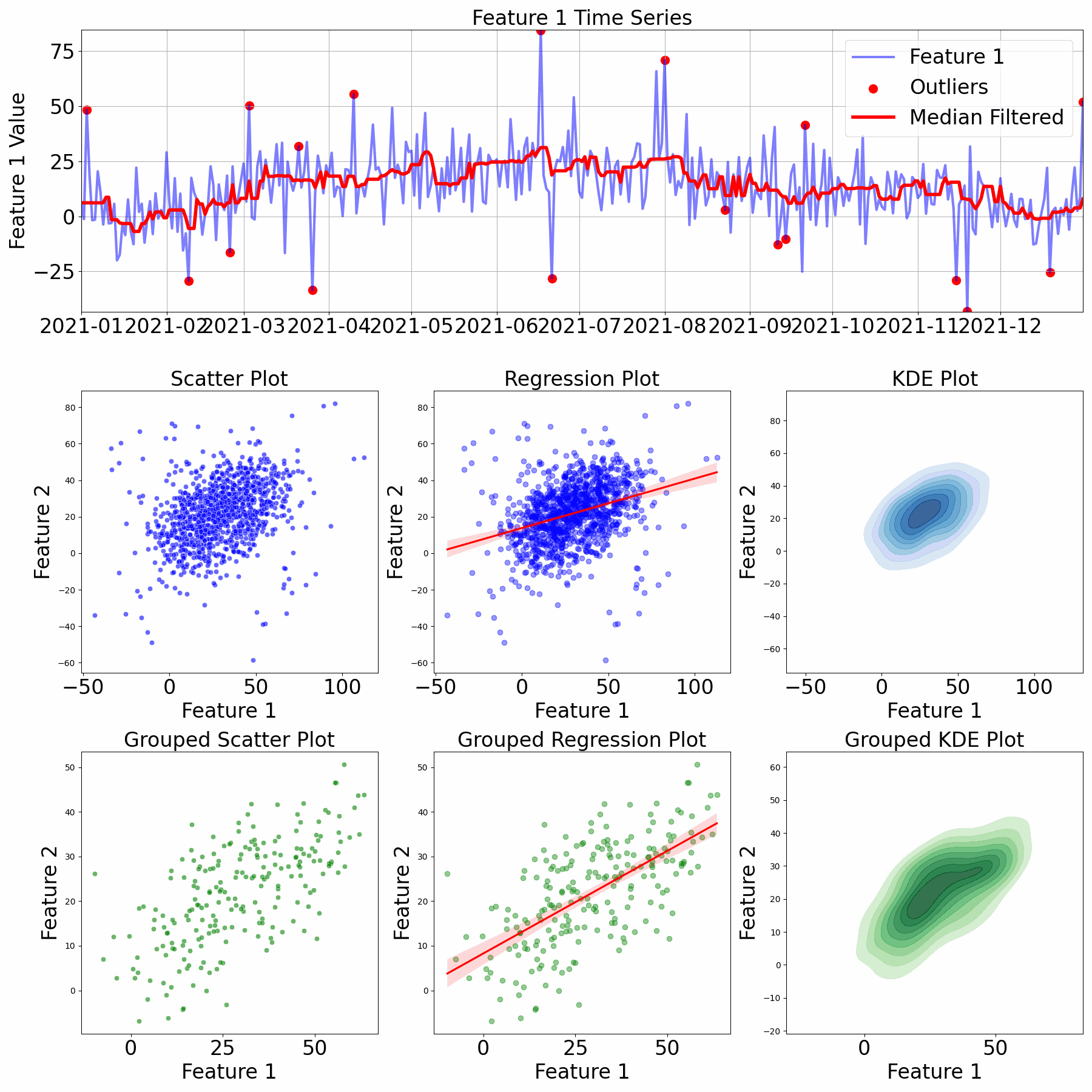
Intro
Data visualization topic in mlcourse.ai
Deeper dive
Below is the list of resources for each library. You can go through the list of plots to understand what kind of plots you can make in general and try several of them. Then, when doing the projects, always go back there and check how to make what you want.
Matplotlib
Seaborn
Plotly
Plotly is good when you need interactive plots. For me, it was useful when I had to go through multivariate time series data.
1.4 Selected Practical Topics
You got some Python exposure. Now, let’s see what else is important to learn as you go. You do not necessarily need to go through it at the beginning but I recommend you to come back when you start working on your portfolio or work projects.
Topic 1: Python environments and how to set it up with Conda
You need to know what an environment is and how to work with it. I recommend starting with Conda and changing later if required.
Topic 2: Demystifying methods in Python
I highly recommend looking at this article because you will often see and use different Python methods and this article gives an excellent explanation.
Topic 3: Python clean code tips and formatting.
- Clean code tips, part 1
- Clean code tips, part 2
- Formatting code with black
- Code linting with flake8 and pylint
2. Data Science / ML introduction
Now we are getting to the “most interesting“ part.
My opinion is that you need to know the basics well to be a solid data scientist. It does not mean to be a nerd, but a good understanding of the main principles will help you in both the job and succeeding in an interview.
In the roadmap, I suggest you get to know only the most often used algorithms but you have to know them very well. Using this knowledge, you can then proceed with other algorithms.
Now, let’s go.
2.1. Introduction
This is a perfect course to get an overview of what machine learning is and what are the two most common problems that are solved by ML: regression and classification. Do not go over the tons of other intro courses, take this.
Note: by default, Coursera is not free but you can ask for financial aid and they will give you that after consideration. I did that several times back in my student days.
2.2. Basic probability, statistics, and linear algebra
Linear algebra
Step 1: Videos of 3blue1brown about linear algebra
Step 2: Tutorial of Python Linear Algebra by Pablo Caceres
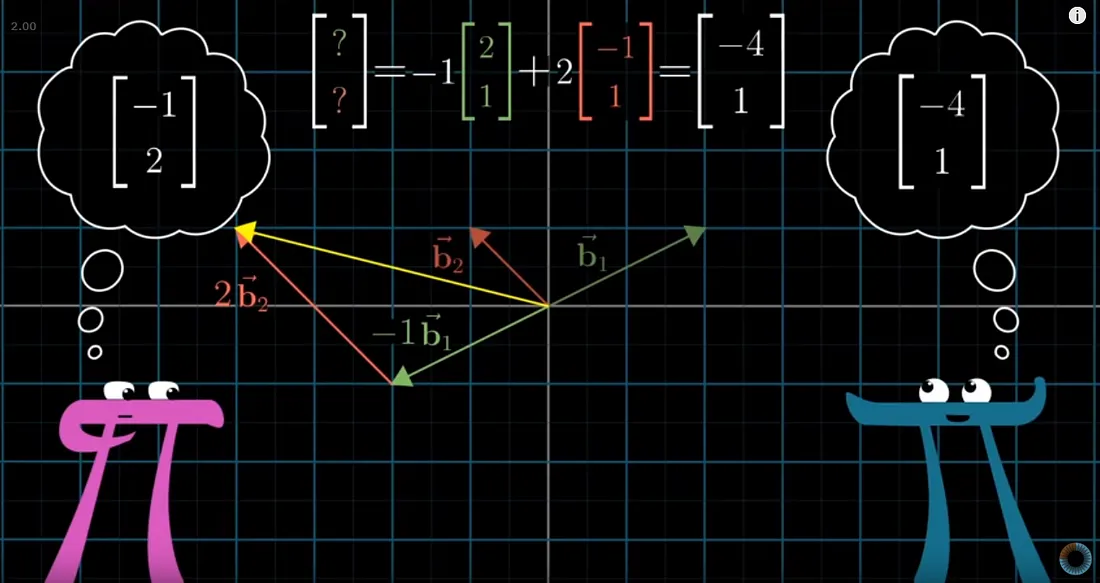
Figure from 3blue1brown YouTube Channel
Probability and Statistics
Step 1: Statistics Crash Course by Adriene Hill
Step 2: Learn Statistics with Python by Ethan Weed
2.3 Supervised learning
There are a massive amount of algorithms but you barely use even 20% of them. I propose you learn the following list and then proceed with the rest using the knowledge you get.
There will be some intersections with Andrew Ng’s course, but it would not hurt to go a bit deeper and have different implementations and perspectives on the same material.
Linear regression
Intro theory: Nando de Freitas lectures at UBC
Python Implementation
Regularization in linear regression

LASSO Regularization and Feature Selection
Regularization is an essential concept to understand and with linear models, you can do it easier. There will be a lot of questions in interviews about it, so make sure you know them.
Step 1: Nando de Freitas lectures at UBC
Step 2: Visual explanation with code
Sklearn tutorial with Lasso model
Logistic regression
Logistic regression is a baseline algorithm for classification tasks. As it is highly related to the linear regression model, you do not need to learn it from scratch but it is important to understand some important concepts about it.
Intro: Logistic regression topic of mlcourse.ai
Selected topic: odds ratio as weights interpretability
Gradient boosting
This one you have to know by heart, I’m sorry. I give you some good resources to start.
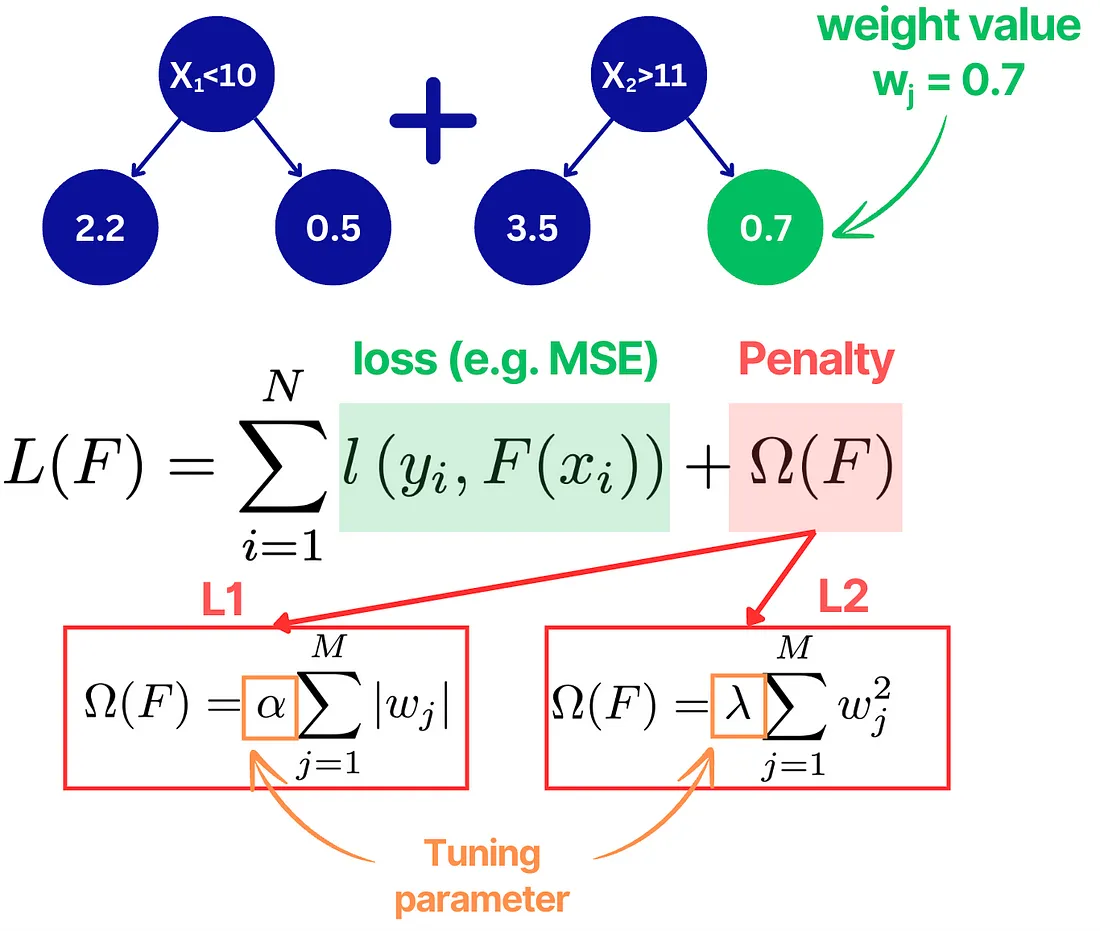
Gradient Boosting Algorithm Structure
Step 1: Gradient Boosting topic of mlcourse.ai
Step 2: Gradient Boosting, deeper dive
I personally learned a lot from the original XGBoost paper, but Natekin’s paper is very detailed and always great to come back to when you forget things.
Step 3: Demo playground by Alex Rogozhnikov
Another genius made a great visualization for us, normal people. By the way, check out his entire blog. It is simply amazing.
Random Forest
Another crucial algorithm to know by heart. Please, understand the difference between Random Forest and Gradient Boosting, I bet you get this question in 30–40% of the interviews.
Step 1: Lectures by Nando de Freitas
Step 2: Bagging topic on mlcourse.ai
k Nearest Neighbours (k-NN)
2.4 Unsupervised learning
You have grown up, my friend. You are ready to know how to learn things from data without knowing what is the true label/value. Let’s see how.
k-Means Clustering
Clustering
Dimensionality reduction
- PCA: Material from the one and famous Sebastian Rashka
- t-SNE
- What is it and how to run it in Python
- How to use t-SNE effectively (with great visualizations) - UMAP
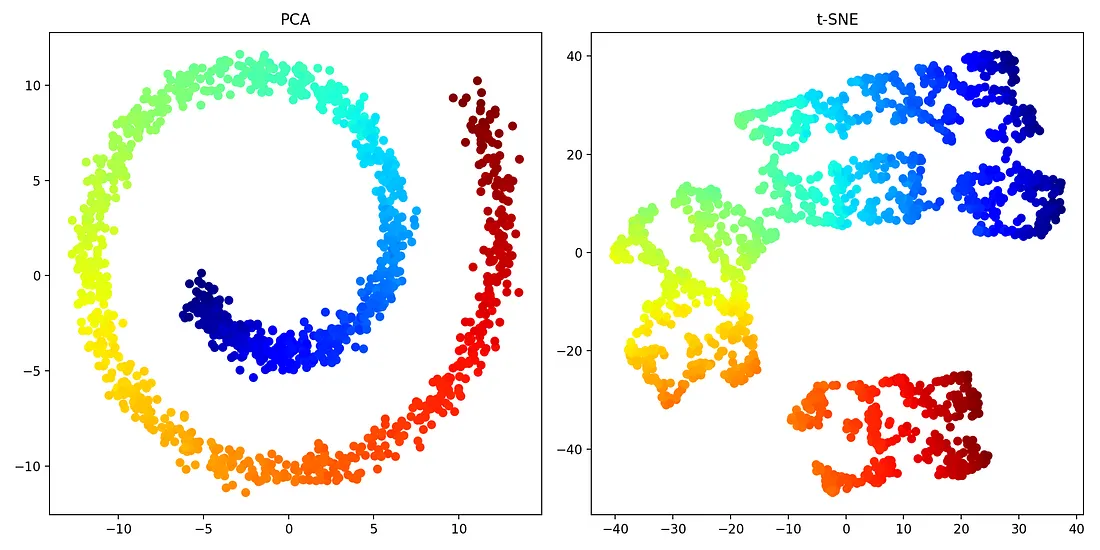
PCA and t-SNE visualization (Source)
3. Data Science / ML Deep dive
3.1 Selected Practical Topics
Feature selection
Feature selection is one of the most important topics when you really want to improve your model, make it more transparent, and understand the WHYs behind the predictions.
Feature importance
Linear methods: Chapter 5 of Interpretable Machine Learning book
- Link 1: https://christophm.github.io/interpretable-ml-book/limo.html
- Link 2: https://christophm.github.io/interpretable-ml-book/logistic.html
Tree-based methods: Youtube Raschka lecture
Permutation feature importance: Chapter 8 of Interpretable Machine Learning book
SHAP: SHAP library documentation
Model metrics evaluation
Ok, you fit the model but then what? Even more, which metric you choose for your problem? The following links provide a good overview about Pros and Cons of the main regression and classification metrics. You might also often see questions about these metrics in the interview.
Regression metrics: H2O blog tutorial
Classification metrics: Evidently AI blog tutorial
Cross-validation
Cross-validation is important to understand to effectively avoid overfitting.
3.2 Neural networks introduction
There are tons of resources on neural networks. It is THE hottest topic. Especially with all the buzz with LLM. In my opinion, to get an intro into the topic, Andrew Ng’s specialization is still great. He goes step-by-step and I guarantee you will understand the concept. From that, you can go deeper depending on the domain you are interested in.
It has 5 courses in it, so take a deep breath.
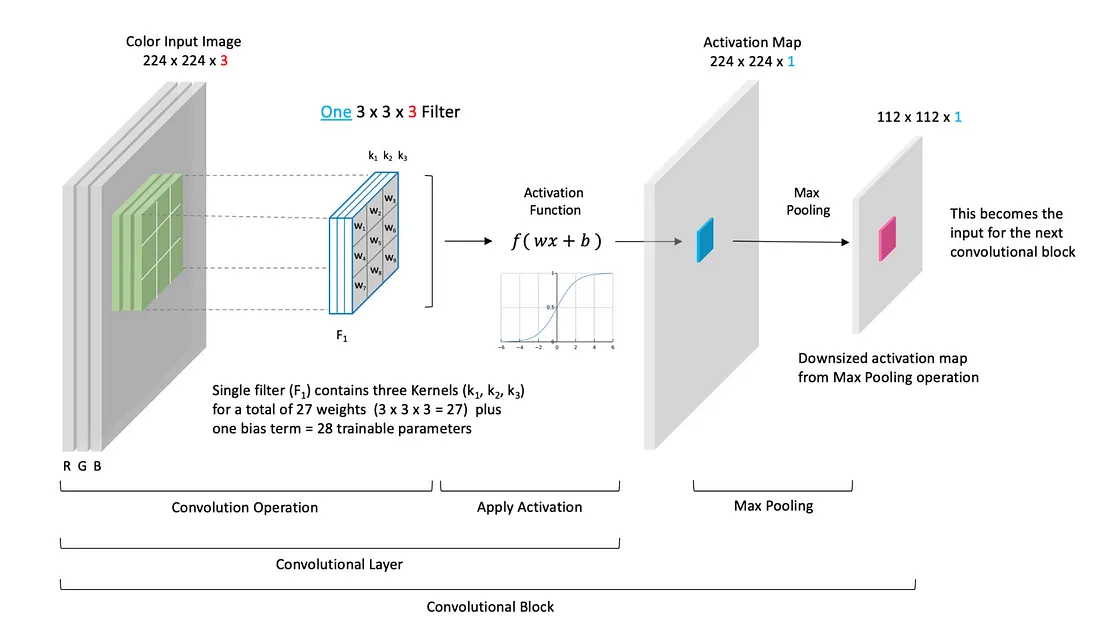
Convolutional Neural Network Block (Source)
3.3 Optimization with Python
Optimization is a relatively hard, heavy-math topic. But it is used in many practical applications. I highly advise you to steadily learn this topic, as it will open great career opportunities.
Introduction to mathematical optimization with Python
This is an AWESOME resource on numerical optimization. Clear examples in Python with mathematical derivations of the basics.
Bayesian Optimization

Bayesian Optimization vs Grid Search vs Random Search
Bayesian optimization is a set of optimization methods that allow optimization of black-box functions using input-output sampling.
Source 1: Awesome playground with theory explanation by distill.pub
Source 2: Tutorial with deep theory dive by Nando de Freitas and Co.
Optimization with SciPy
There are various optimization Python libraries you can use for optimization. SciPy is very often used for it. If you come across the need to use SciPy for this, look at these resources:
Interactive playground of several optimization methods
Sometimes it is useful to play with parameters and see how the algorithm works. Here is a great playground with a couple of methods.
Additional resources
3.4 Signal processing
Signal processing is often an essential part of an ML projects because you have to be able to filter data from noise outliers and other dirty stuff.
Paid source:
I highly recommend a paid course by Mike Cohen. For this price and quality, I consider it essentially free. I have completed the course myself and like it a lot. Since then, I have applied several methods from the course in practice.

Time Series Filters (Image by Author)
Free resources:
If you want fully free alternatives, here are some links on filtering and Fourier transform.
Mean filter
Median filters
Exponential smoothing
Gaussian filter
Fourier transform
Low and high pass filters
3.5 Anomaly detection
In addition to modeling and optimization, another large class of ML problems are related to anomaly detection. I gathered a list of resources to get an overview of the problem and applied methods to solve it.
Review of anomaly types and detection methods
Good overview with Python examples
List of libraries for time series anomaly detection
Selected articles:
4. MLOps for data scientists
There will always be a debate if data scientists need to know MLOps / machine learning engineering.
MLOps is a huge field itself, but you will be a much stronger professional who can build things from end-to-end on a decent level alone or a solid level within a team of ML engineers.
In this roadmap, I provide you with basic resources to start, so with some digging, you can do a decent job of preparing your models for deployment.
4.1 Introduction
Alexey Grigoriev with a team created a great intro course on MLOPs and I will be referring to his course several times. I suggest you take the whole course, but here I mention specific topics.
Another amazing resource is the neptune.ai blog. They do a fantastic job! I will be mentioning their resources all the way.
I suggest you take a look at his intro videos that do not concern the course environment setup.
4.2 Model registry and experiment tracking
Model registry and experiment tracking are required to develop a consistent workflow of model creation and deployment, especially if you work in a team. Here are some resources to get an intro about it:
- Source 1
- Source 2
- A hands-on example of how to perform experiment tracking and create a model registry.
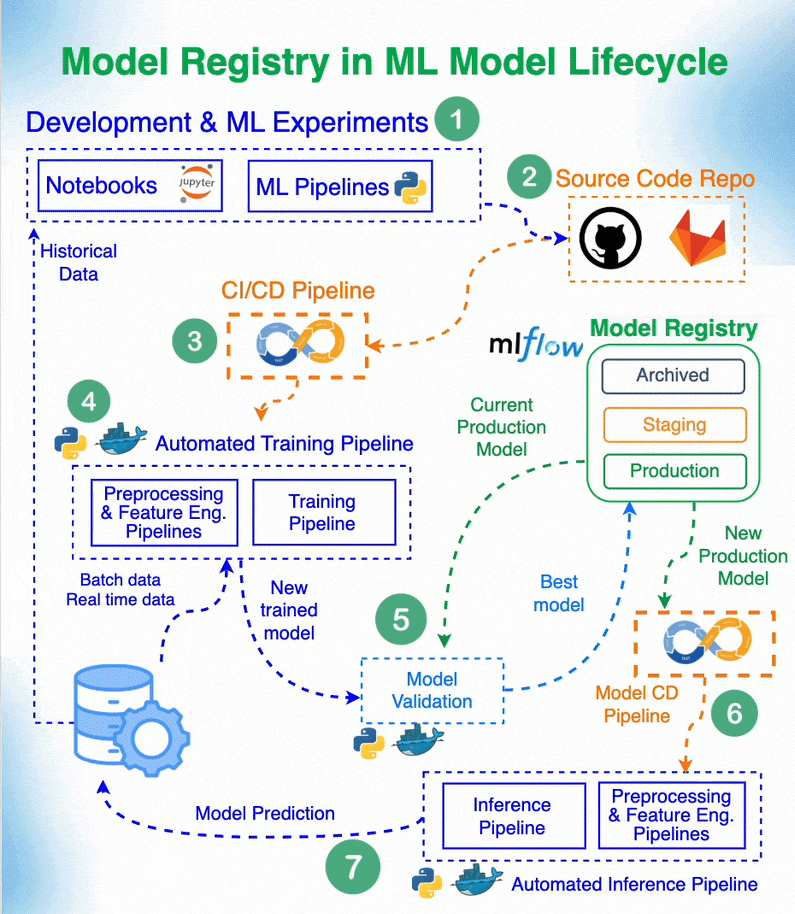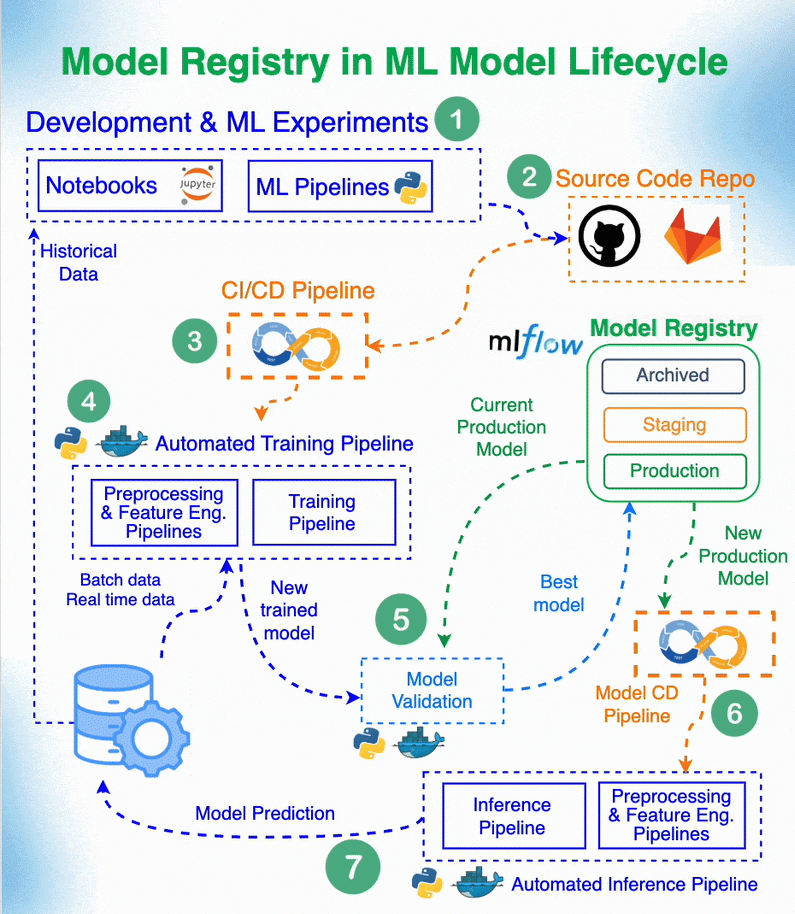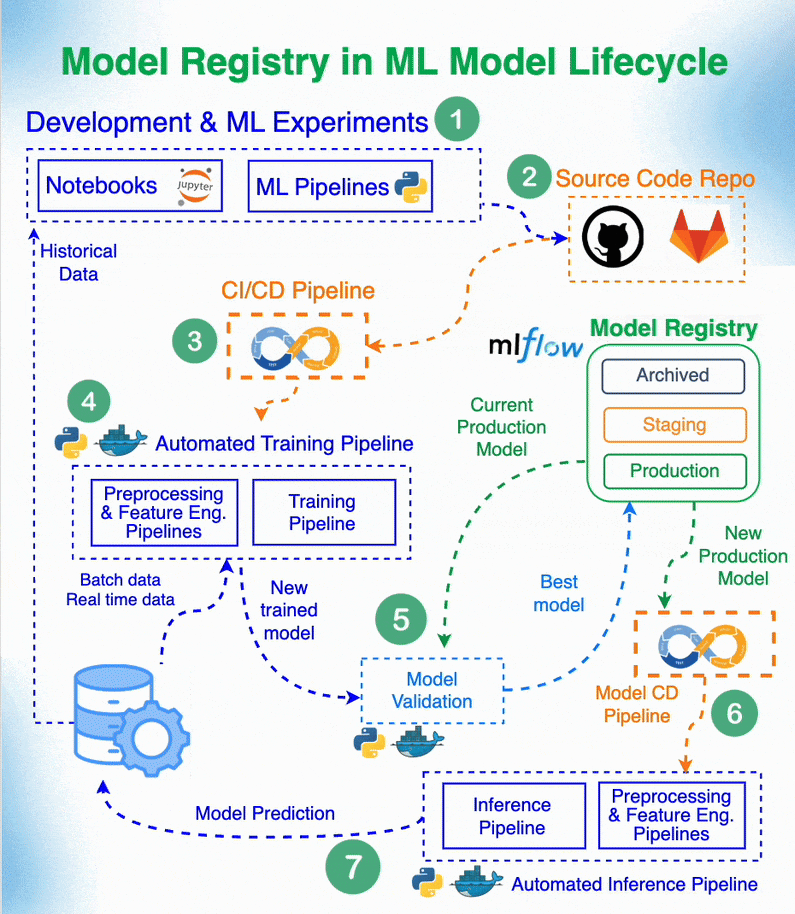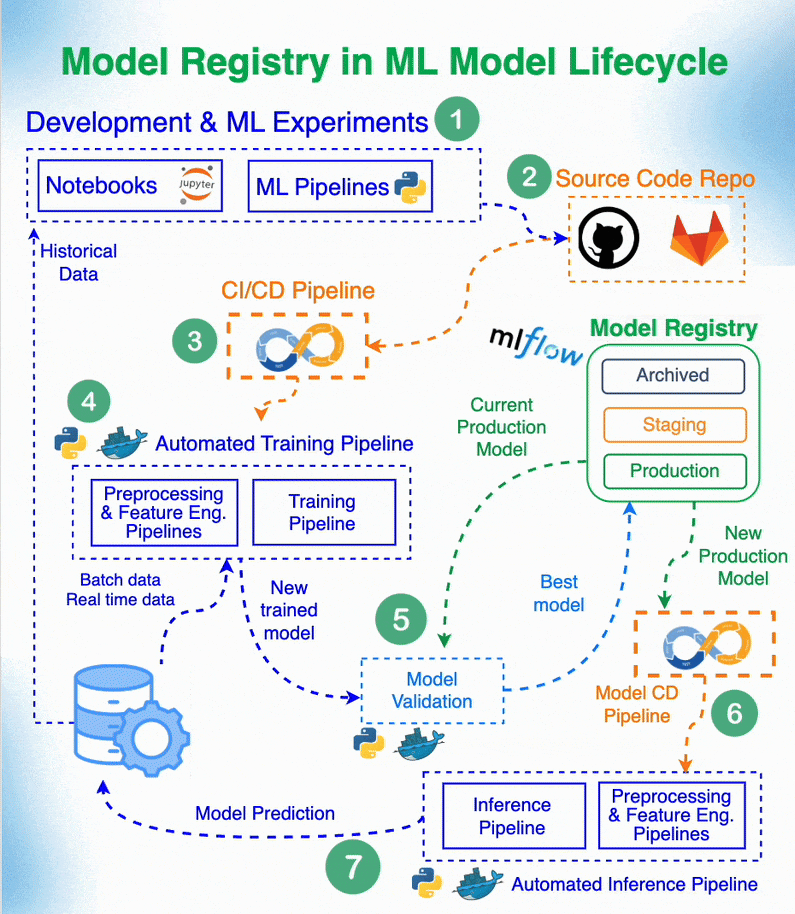
Model Registry Role in Machine Learning
4.3. ML Pipelines
In my opinion, a data scientist MUST know how to create good clear machine learning pipelines. It is a misery to see still people making terrible hard-coded pipelines while there are many pipeline-building tools. I recommend you do the following:
Step 1: Get an intro to what ML pipelines are and what are the available tools for it:
Step 2: Complete a section of the MLOps zoomcamp with Mage / Prefect (previous years)
Step 3: Take a very simple dataset and make a new pipeline with any tool you like without guidance
4.4 Model Monitoring
Model monitoring is another essential topic that comes after model development. This is the weakest point of all ML solutions I have seen and built so far.
For learning model monitoring, there is no better place than the blog of evidentlyai.com. They also host the model monitoring section on MLOps zoomcamp.
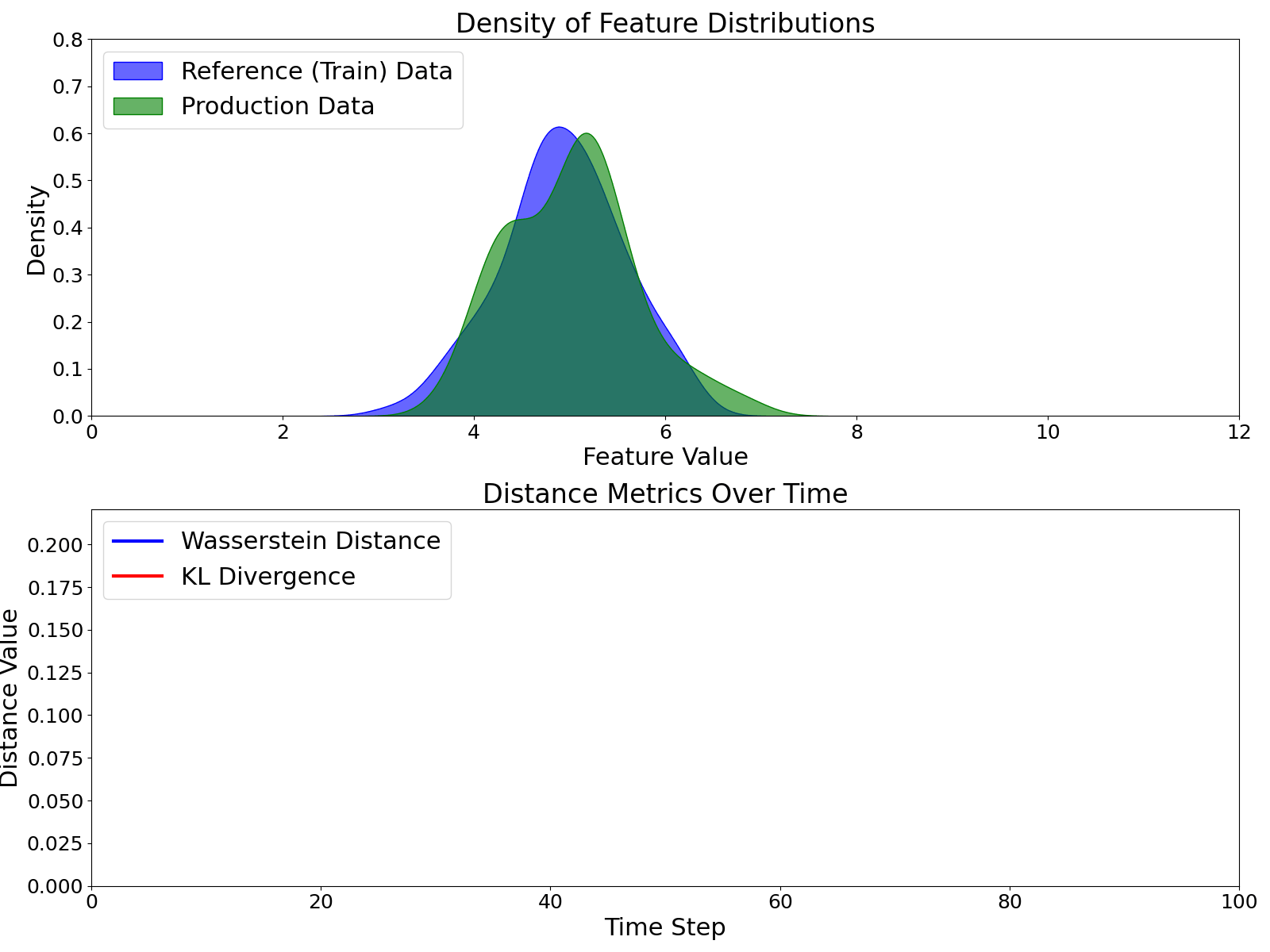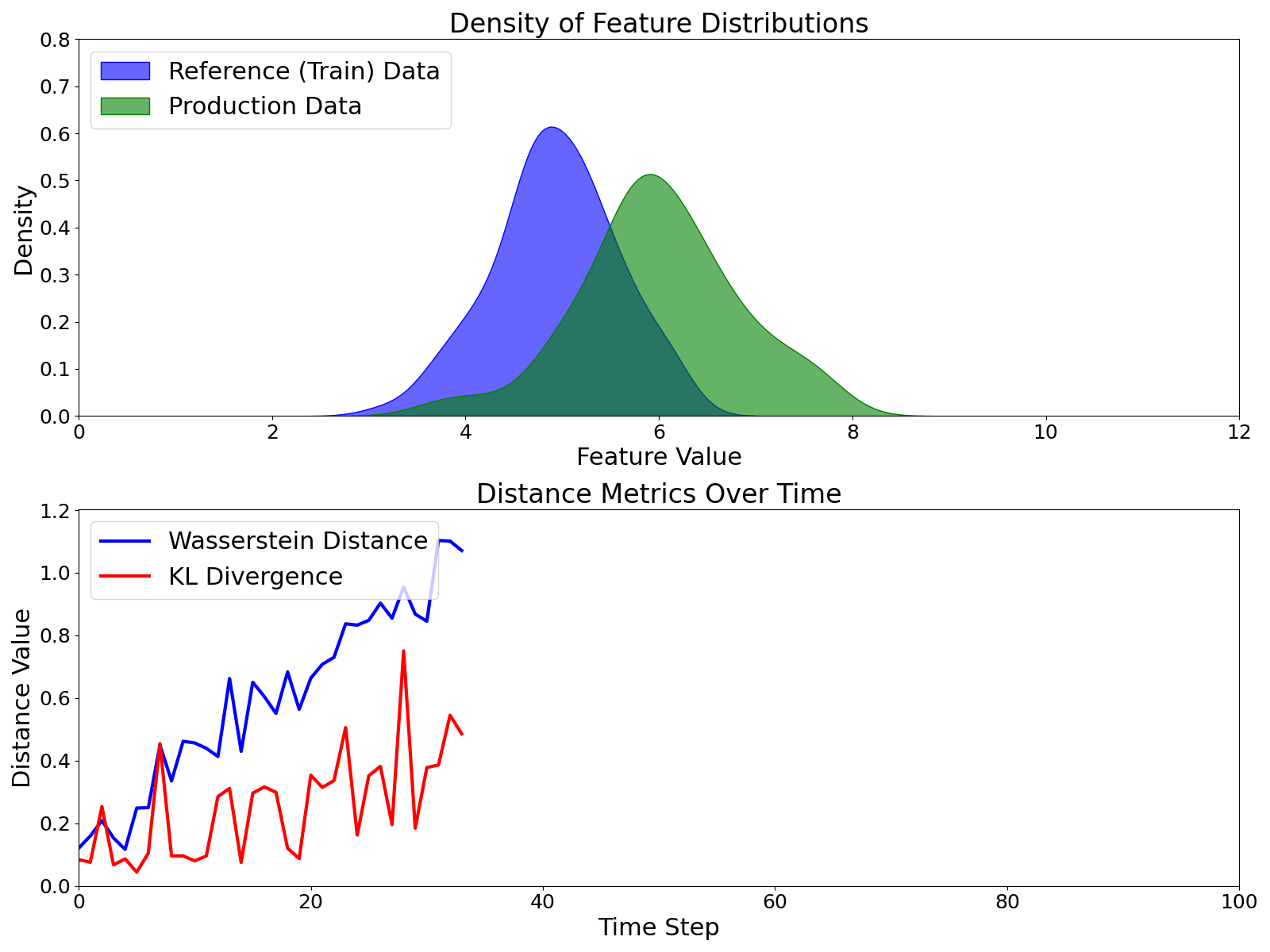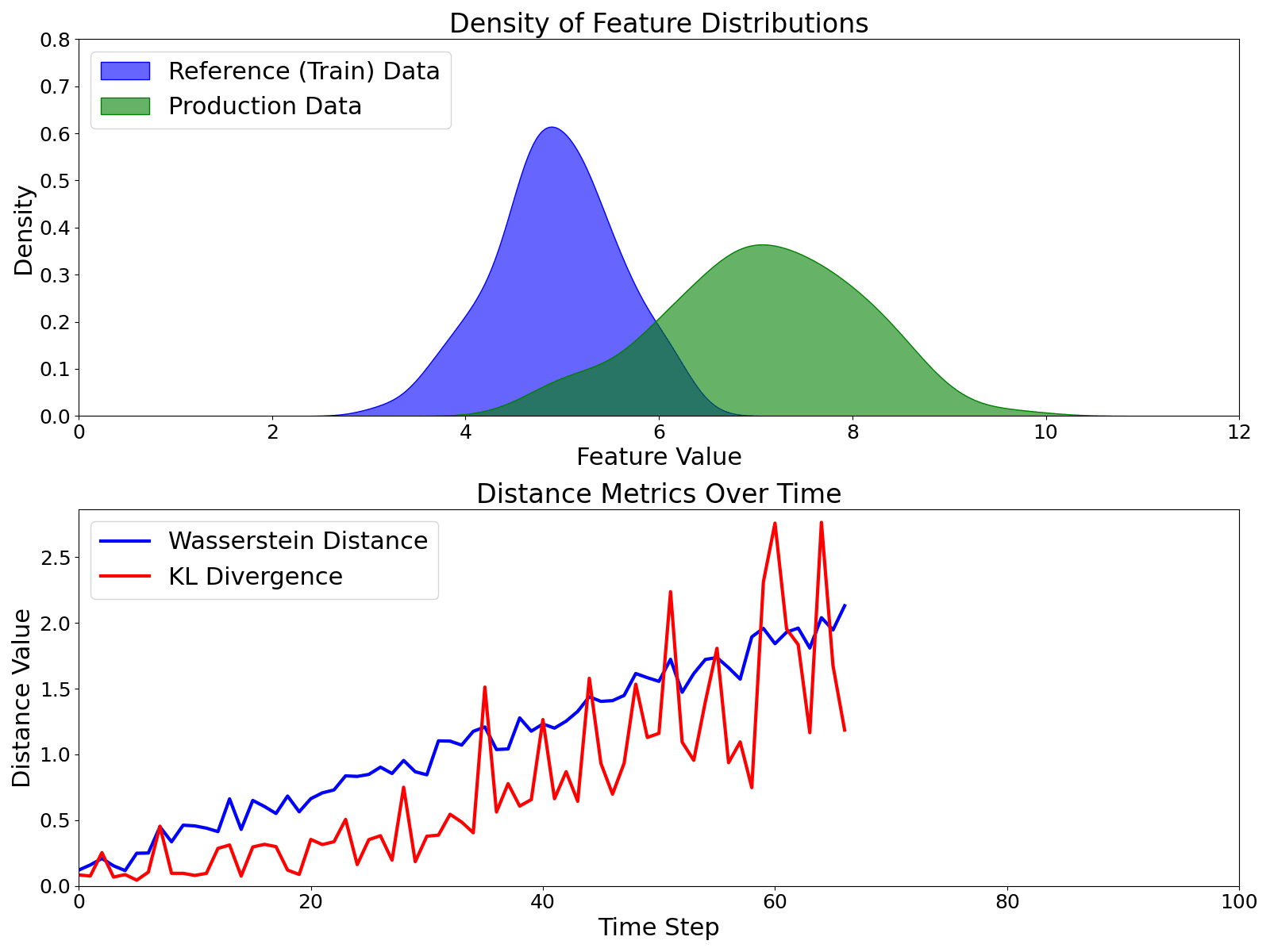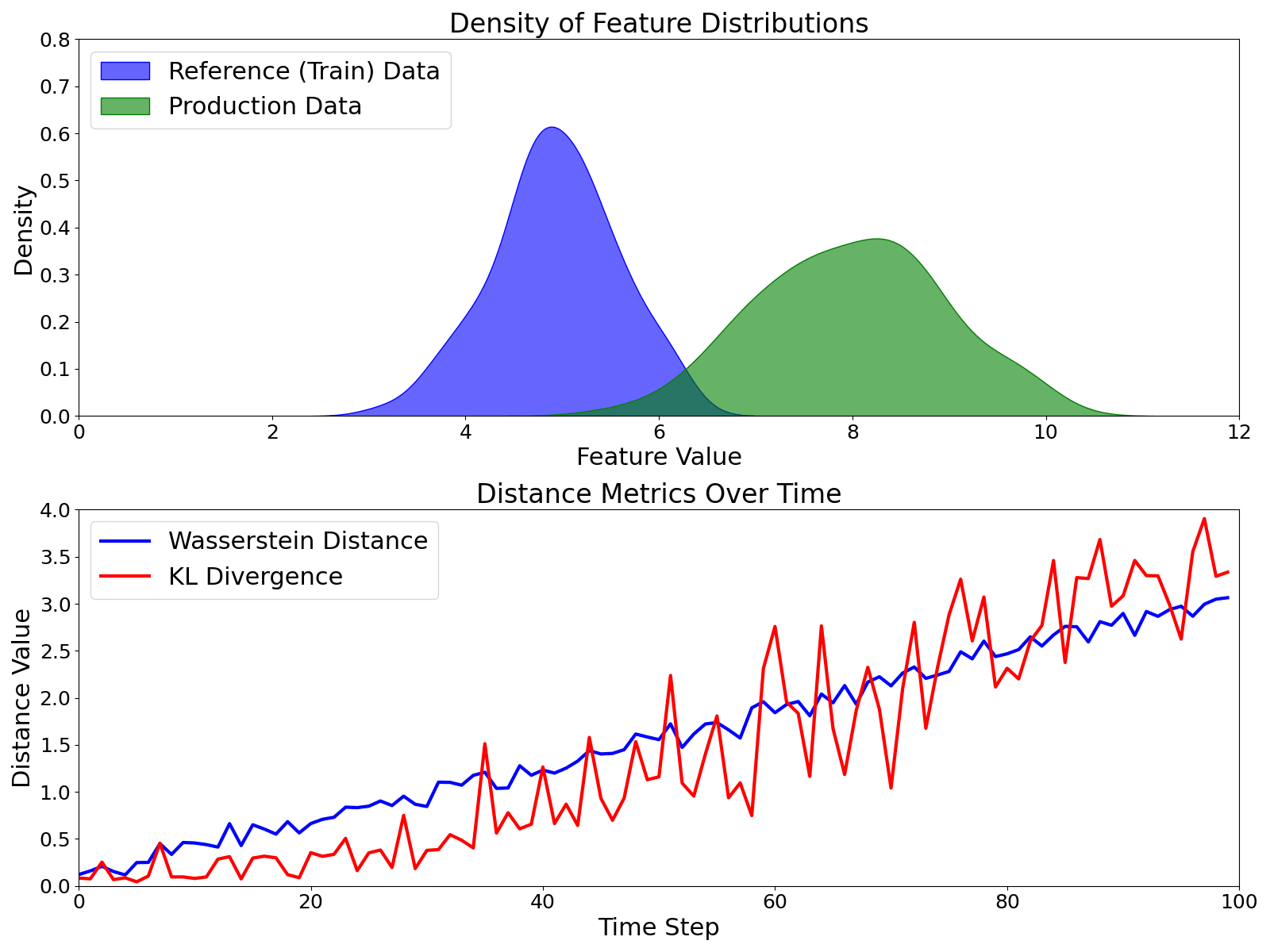
Metrics for Data Drift Monitoring
4.5 Docker basics
Docker is a tool/platform that allows one to build, share, and run container applications that are reproducible in any new environment. Docker is always scary for data scientists because, come on, what the hell is that? I am with you.
However, the truth is that docker is not that difficult, at least at the level that data scientists should know it.
To start, I recommend a great crash course by Nana
4.6 Additional resources
If you feel you want to go deeper into some of the topics, you may want to look at the MLOps roadmap.
However, my warning is that you need to be careful because it is not possible to know everything. So, make sure you understand the basics that you need at your job or to make portfolio projects, and then move on slowly.
📌 That’s it! But 2 more things…
- If you like the roadmap, you will also like my weekly newsletter! SUBSCRIBE HERE!
- Every day, I also post Machine Learning Content on LinkedIn, follow me!