Machine Learning Pipelines: Ad-hoc vs Frameworks
Mar 08, 2025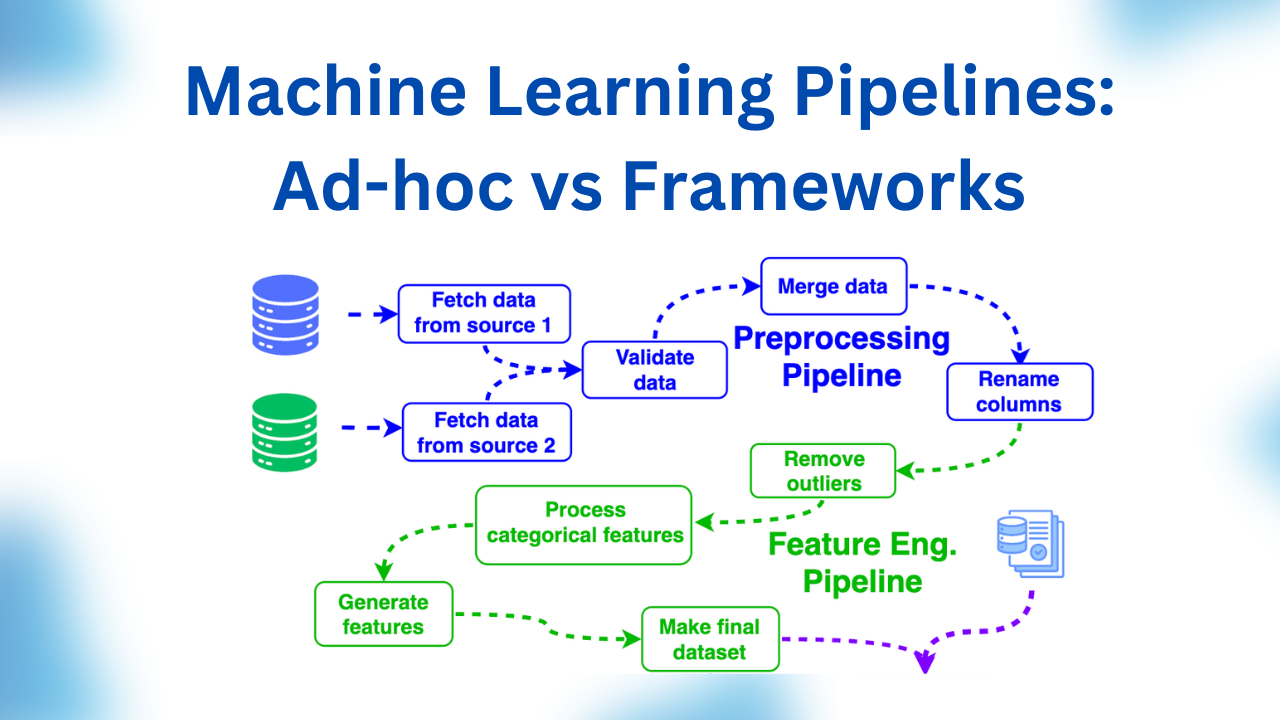
Estimated reading time - 7 minutes
Intro
In my ML career, I've seen many Machine Learning pipelines developed for a variety of projects. Different teams have different visions of how the ML pipelines should be written and configured.
In many cases I saw how teams develop complex pipelines with even more complex config files that made the projects hard to understand and maintain.
In other cases, I worked and led teams where open source pipeline and orchestration frameworks were used to create ML pipelines. This allowed me to see advantages and disadvantages of this approach and compare it with fully self-made pipelines.
In this article, we'll compare the Pros and Cons of each approach and when to choose which (fully based on my experience and understanding).
What is a Machine Learning Pipeline?
There are several definitions of what is an ML Pipeline. In this article, we will call a Machine Learning pipeline a workflow that includes the following standard steps:
-
Data Preprocessing
-
Feature Engineering
-
Model Training
-
Inference
-
Data Postprocessing
This is what a typical ML pipeline can look like.
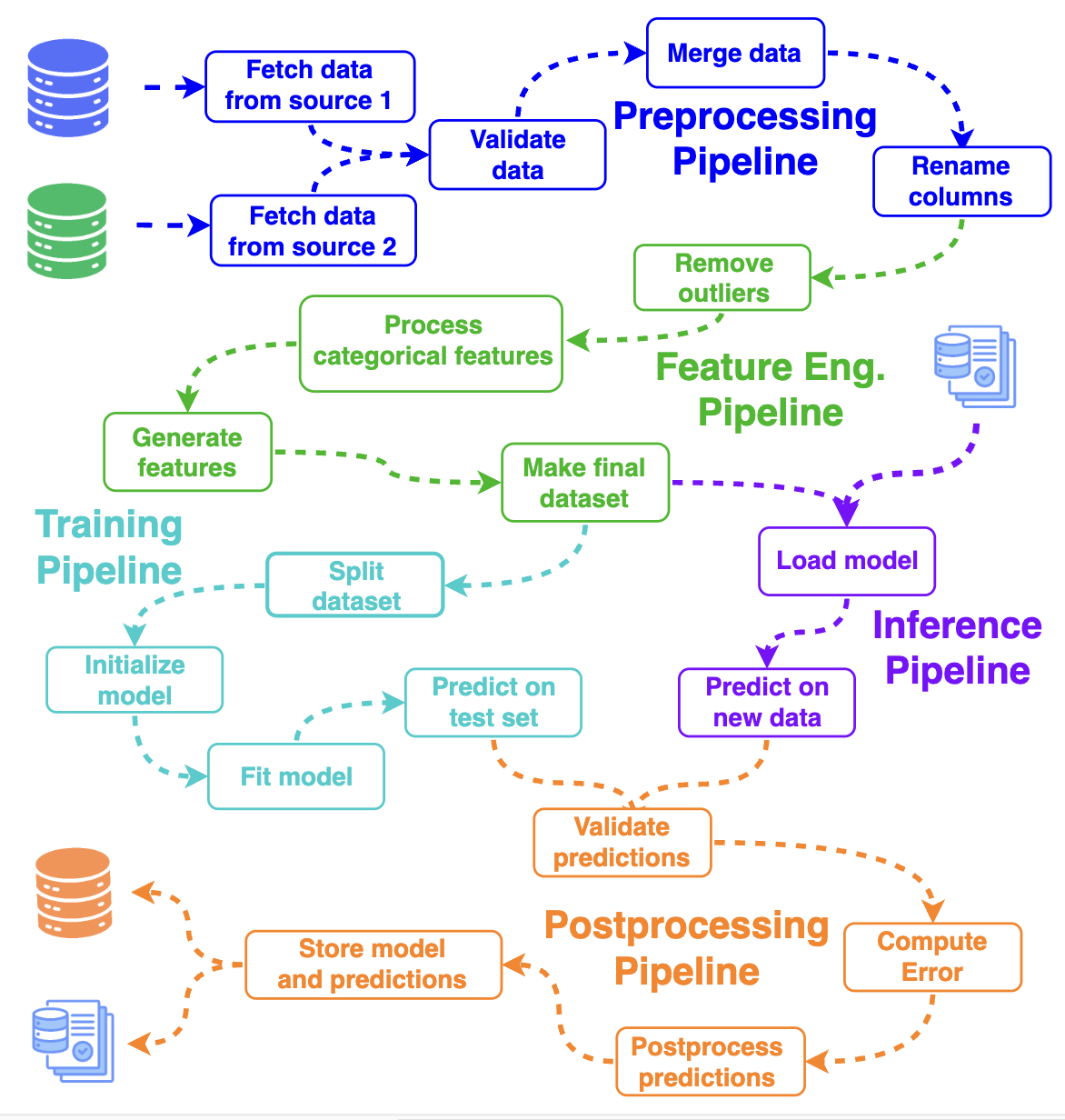
Typical Machine Learning Pipeline
In most cases, an ML pipeline is a Directed Acyclic Graph (DAG) which consists of nodes (typically Python functions) and edges which correspond to data transfers of different kinds and define relationships between the nodes.
Ad-hoc vs Framework ML Pipelines
As you can imagine, you can construct such pipelines purely from scratch. All you need is:
- data storage
- model storage
- collection of Python functions
- pipeline configuration setup
Here, the pipeline configuration setup defines a set of config files which allow flexible adjustments of the pipeline structure and behavior during the development, testing and production phases.
Having these components in place, the pipeline can be created with 2 main approaches:
Ad-hoc ML Pipelines
These pipelines are manually developed using a collection of Python functions, data storage solutions, model storage, and a configuration setup. Teams using ad-hoc pipelines need to implement logging, monitoring, and orchestration manually, which can be time-consuming and challenging as the project grows.
Since they are built from the ground up, they offer maximum flexibility. But here comes the first catch: because there are so many ways you can create these pipelines and configuration files, it can lead to many development and deployment problems.
This is what ML pipeline frameworks / workflow managers come into play.
ML Pipeline Frameworks
Framework-based pipelines standardize ML workflows. These frameworks provide built-in features like configuration management, logging, orchestration, and dependency tracking, which improve maintainability and scalability.
While they may require an initial learning curve, they significantly reduce development time and ensure consistency across projects.
The main open-source ML Pipeline Frameworks are:
- Airflow
- Kedro
- MetaFlow
- Flyte
- Prefect
Among these frameworks, some are more oriented for ETL Pipelines and Orchestration and workflow orchestration (Airflow, Prefect) while others are focued on more ML Pipelines themselves with Data Scientists as the main users (Kedro, MetaFlow, Flyte).
Evaluation Criteria
We will evaluate building ad-hoc pipelines vs frameworks based on the following criteria:
- Pipeline structure observability
- Configuration flexibility
- ML project structure
- Development Speed
- Maintainability
Let's get straight into comparison.
Pipeline Structure Observability
Pipeline structure observability refers to the ability to track, monitor, and visualize the execution of an ML pipeline. This helps teams debug issues, understand dependencies, and ensure smooth operation in production environments.
-
Ad-hoc Pipelines:
-
No built-in visualization and logging.
-
Debugging is difficult due to lack of standard tracking.
-
Requires manual setup for observability.
-
-
Framework-based Pipelines:
-
Provides built-in visualization tools such as DAG views and logs.
-
Easier debugging due to structured monitoring.
-
Standardized tracking of pipeline execution and errors.
-
Here is an example of visualization of a pipeline structure using Kedro Pipeline Manager.
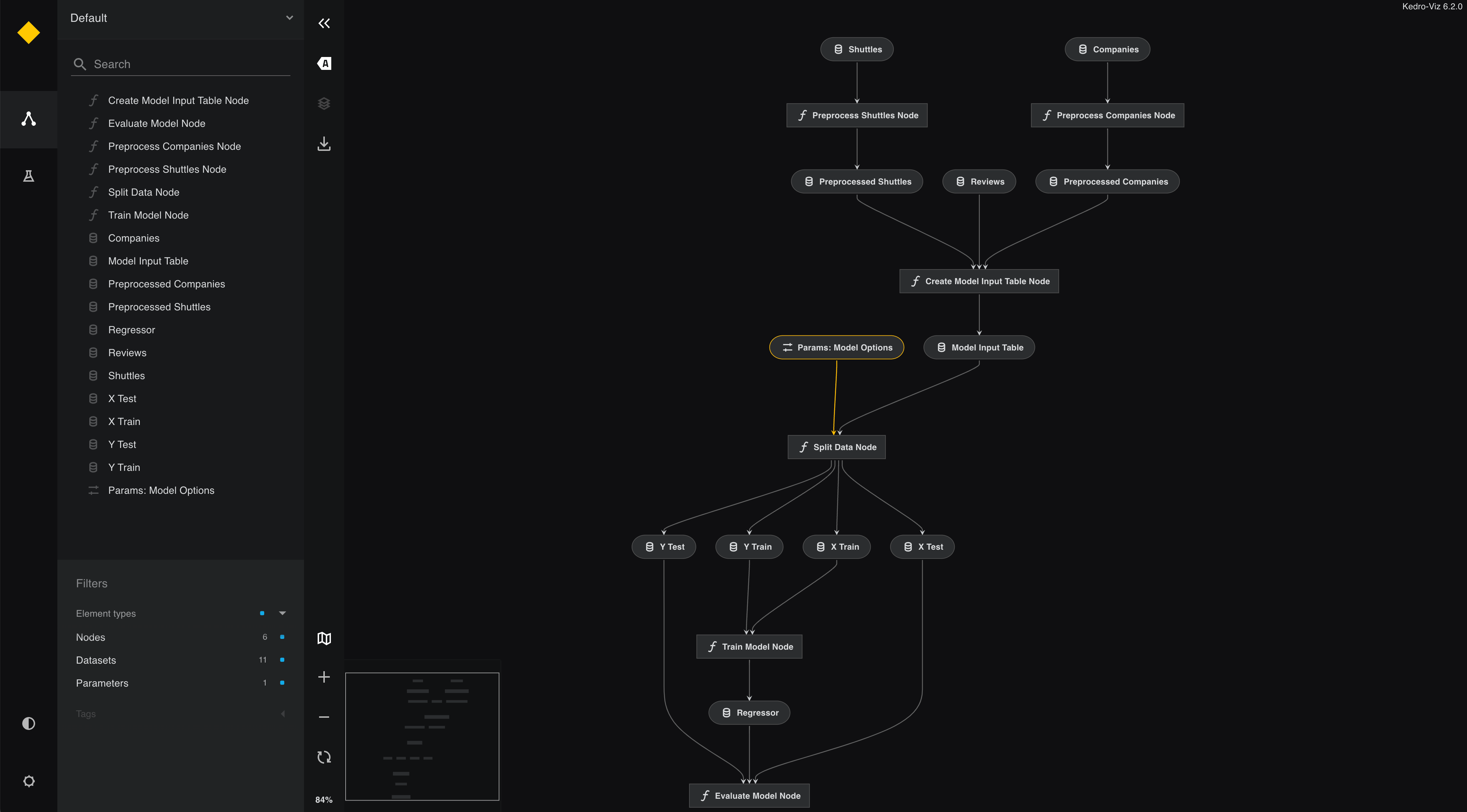
Kedro ML Pipeline Visualization (Source: Kedro Documentation)
Configuration Flexibility
Configuration flexibility defines how easily a pipeline's settings can be adjusted during different phases of development, testing, and production. A well-structured configuration system ensures adaptability without excessive complexity.
-
Ad-hoc Pipelines:
-
Fully customizable but usually lacks standardization.
-
Requires manual implementation of configuration parsing.
-
Can lead to complex and hard-to-maintain configuration files.
-
-
Framework-based Pipelines:
-
Usually provide standardized YAML/JSON/TOML-based configuration management
-
Enforces structure, reducing complexity in setup, easier to reuse configurations across different projects.
- Can be less flexible for specific use cases.
-
ML Project Structure
A well-organized ML project structure improves collaboration, code maintainability, and consistency across teams. Without a structured approach, projects can quickly become unmanageable as they grow.
-
Ad-hoc Pipelines:
-
No enforced structure; project organization depends on the developer.
-
High risk of inconsistency in codebase and folder structure.
-
Harder to maintain and reuse across teams.
-
-
Framework-based Pipelines:
-
Enforces best software engineering and MLOps practices.
-
Standardized directory structure improves maintainability.
-
Easier to scale and share across teams.
-
A good example of the project structure support is Kedro framework.It borrows concepts from software engineering and applies them to machine-learning projects, see the image below. In the Kedro case, this structure is created automatically by 1 CLI command.
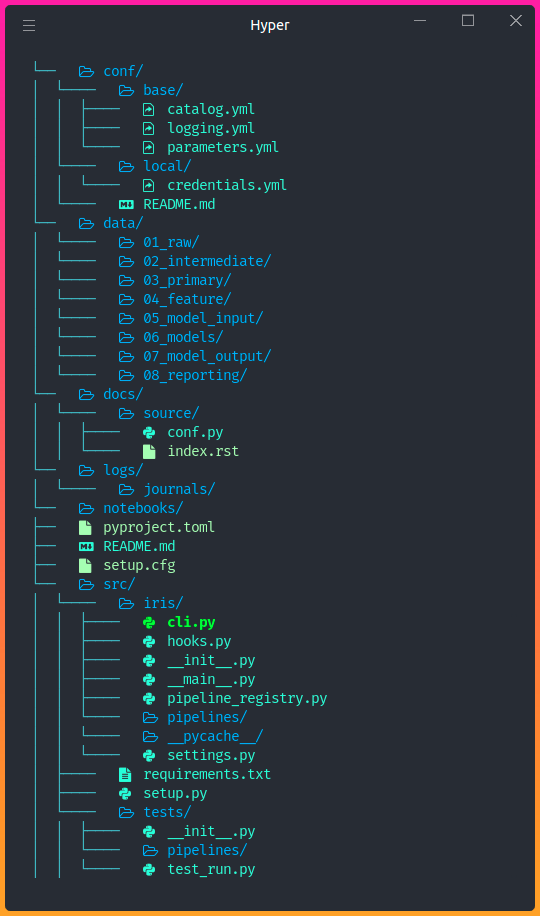
ML Project Structure based on Kedro Framework (Source: Medium Blog)
Development Speed
Development speed refers to how quickly a team can build, iterate, and deploy ML pipelines. Faster development cycles improve productivity and reduce time to market for machine learning solutions.
-
Ad-hoc Pipelines:
-
Slower long-term development: requires building many tools from scratch (e.g., caching, retries, and dependency resolution).
-
Higher development time as everything needs to be manually integrated.
-
Risk of reinventing the wheel with inefficient implementations.
-
-
Framework-based Pipelines:
-
Faster long-term development with built-in tools.
-
Encourages best practices and standardization.
-
May be slower for quick prototyping due to initial setup and learning curve.
-
Maintainability
Maintainability is the ease with which an ML pipeline can be updated, debugged, and extended over time. Well-maintained pipelines minimize technical debt and ensure long-term viability.
-
Ad-hoc Pipelines:
-
Lack of observability and standardization makes it harder to maintain
-
Debugging and modifications require additional effort.
-
-
Framework-based Pipelines:
-
Standardized approach improves maintainability.
-
Built-in observability tools facilitate debugging.
-
Easier debugging and long-term maintainability.
-
Summary: When to use each approach?
Here is a comparison summary table
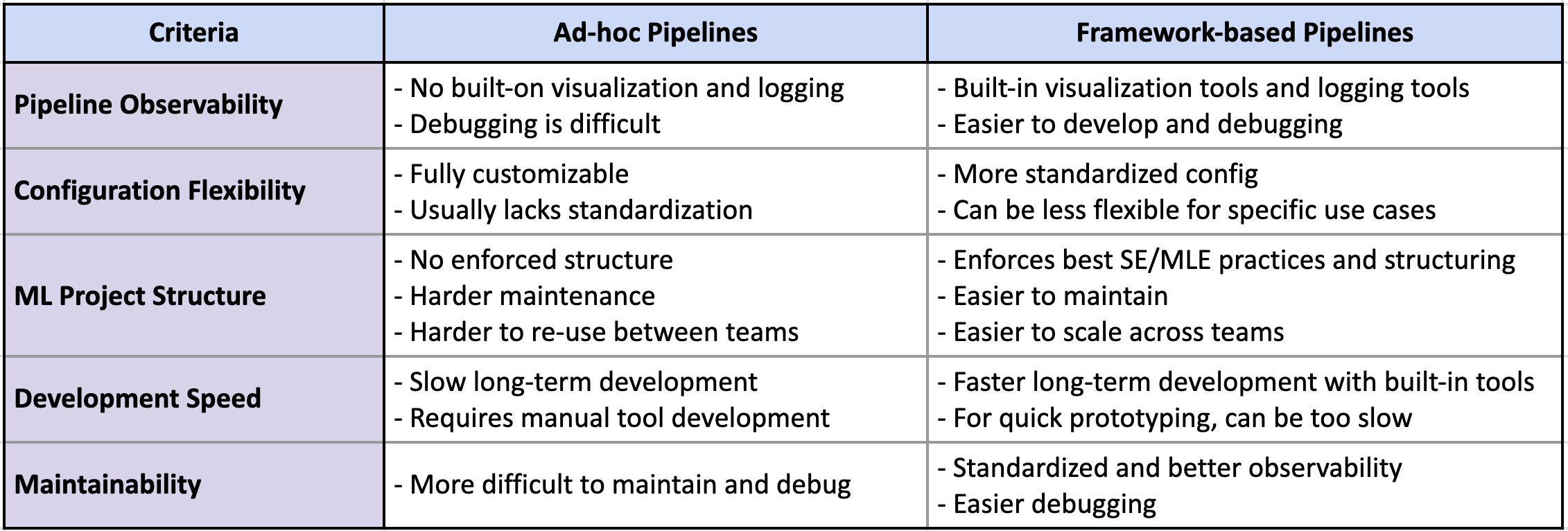
Use Ad-hoc Pipelines When:
-
The project is small and experimental.
-
There is no immediate need for scaling or maintenance.
-
Full control over pipeline design is required specific for a use case.
Use Framework-based Pipelines When:
-
The project is large, complex, and expected to grow.
-
Standardization, maintainability, and collaboration are priorities.
-
There is a need for robust orchestration, logging, monitoring & long-term support.
In the next blog articles, we will closely look at different pipeline frameworks, deployment strategies and more.
Subscribe to my newsletter below to receive the articles straight to your inbox!