5 Tips for Writing Machine Learning Pipelines
Mar 22, 2025
Estimated reading time - 7 minutes
The ML Pipeline Challenge
Most Data Scientists don’t come from a Software Engineering background, so key coding best practices are often unfamiliar to them.
Yet, these days, Data Scientists are often expected to build end-to-end ML solutions, including pipelines that run in production.
Without solid Software engineering principles, these pipelines often end up messy, inflexible, and fragile - especially without proper code reviews from experienced ML/MLOps engineers.
I’ve seen so many poorly ML Pipelines, so I’ve selected 5 most common bad coding practices of writing ML Pipeline and tips on how to solve them.
Bad Practice 1: Hardcoding Parameters in Code
Here is what parameter hardcoding might look like:
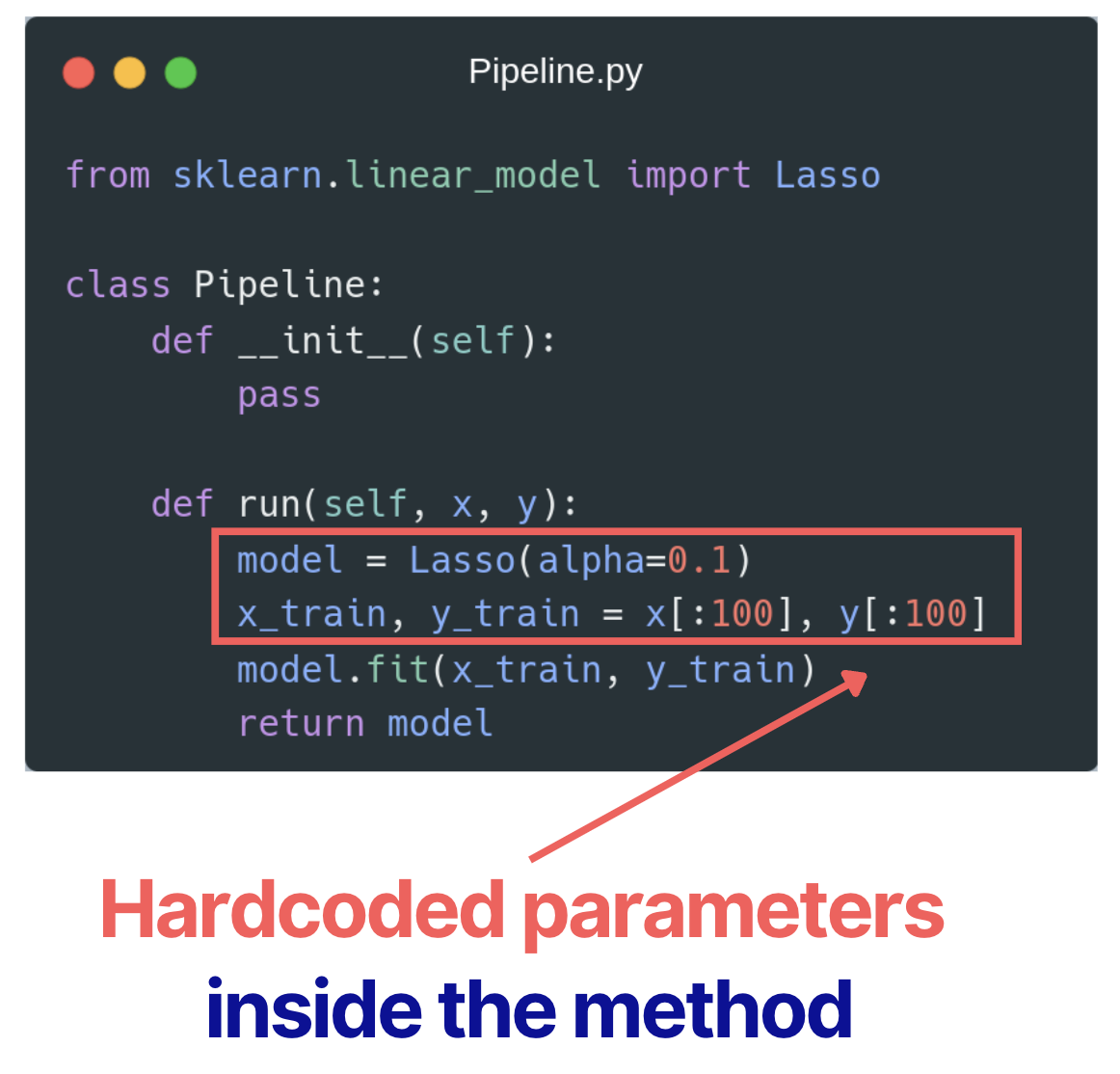
🟠 Hardcoding leads to:
-
Difficulty in making changes if the codebase is big
-
Difficulty in adapting parameters for similar modeled objects without lengthy "if-else" statements.
-
Need for re-deployment if the parameters need to be changed.
✅ Solution:
Use a Configuration (config) File and write the entire ML Pipeline such that the parameters that might change are extracted from this config file. Here is an example:

Config allows:
- Easy finding and changing parameters in one place
- Avoiding re-deployment of an ML application, parameters can be changed on the fly
- Flexible selection of these parameters in the code, e.g. hyperparameters tuning.
Bad Practice 2: Ignoring Modularization
Here is what ignoring modularization might look like:

🟠 Ignoring modularization leads to:
- Poor code readability and difficulty in following data transformation
- Difficult maintenance and testing
- Code repetition and limited reusability
✅ Solution:
- Split the code into functions (class methods)
-
Ideally, one function should perform one task
-
Good practice for “run” method in the pipeline class is only to call other methods

Bad Practice 3: Avoiding type annotations and documenting the code
Here is an example:
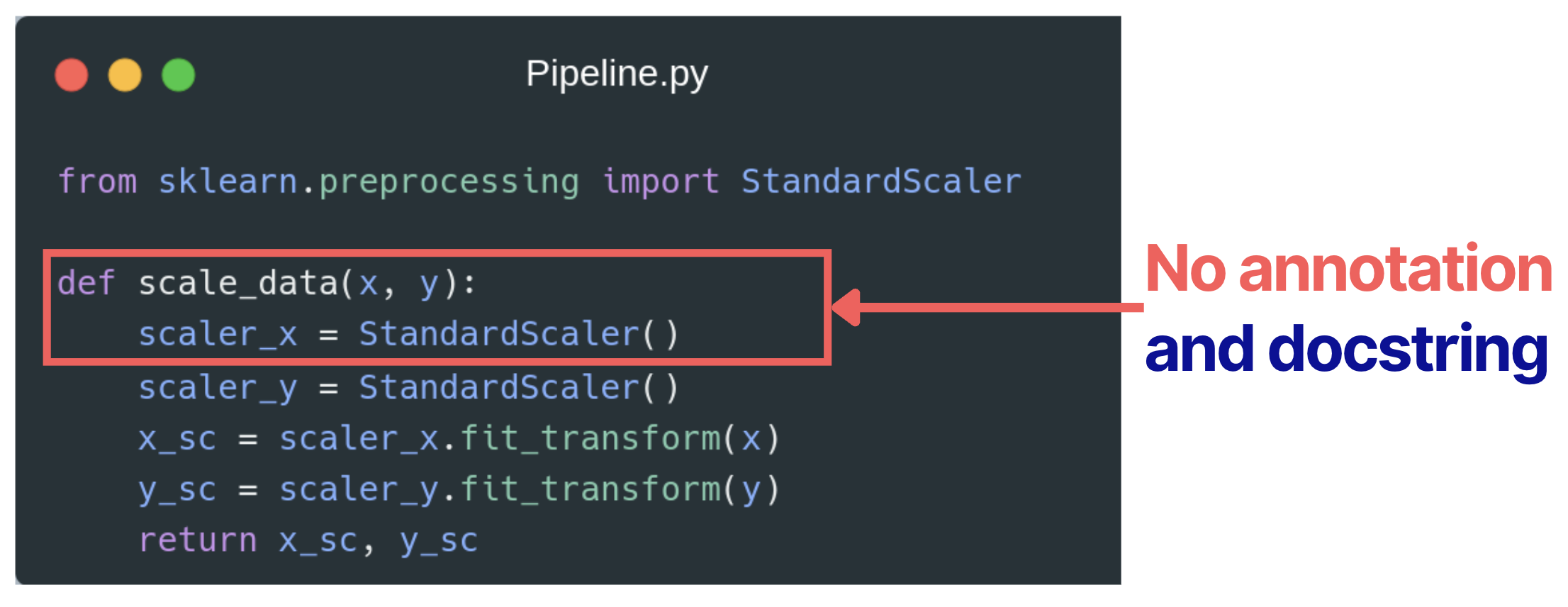
🟠 Ignoring proper code documentation leads to:
- Poor code readability, especially for other developers
- Inability to check type-related issues for linters
- Poor maintainability, especially in big codebases
- Inability to produce high-quality code documentation
✅ Solution:
Add typing annotations, docstrings and comments to your code.
Below is an example of the fixed code. Even in this simple case, we can see that we change the data type from a DataFrame to NumPy arrays.
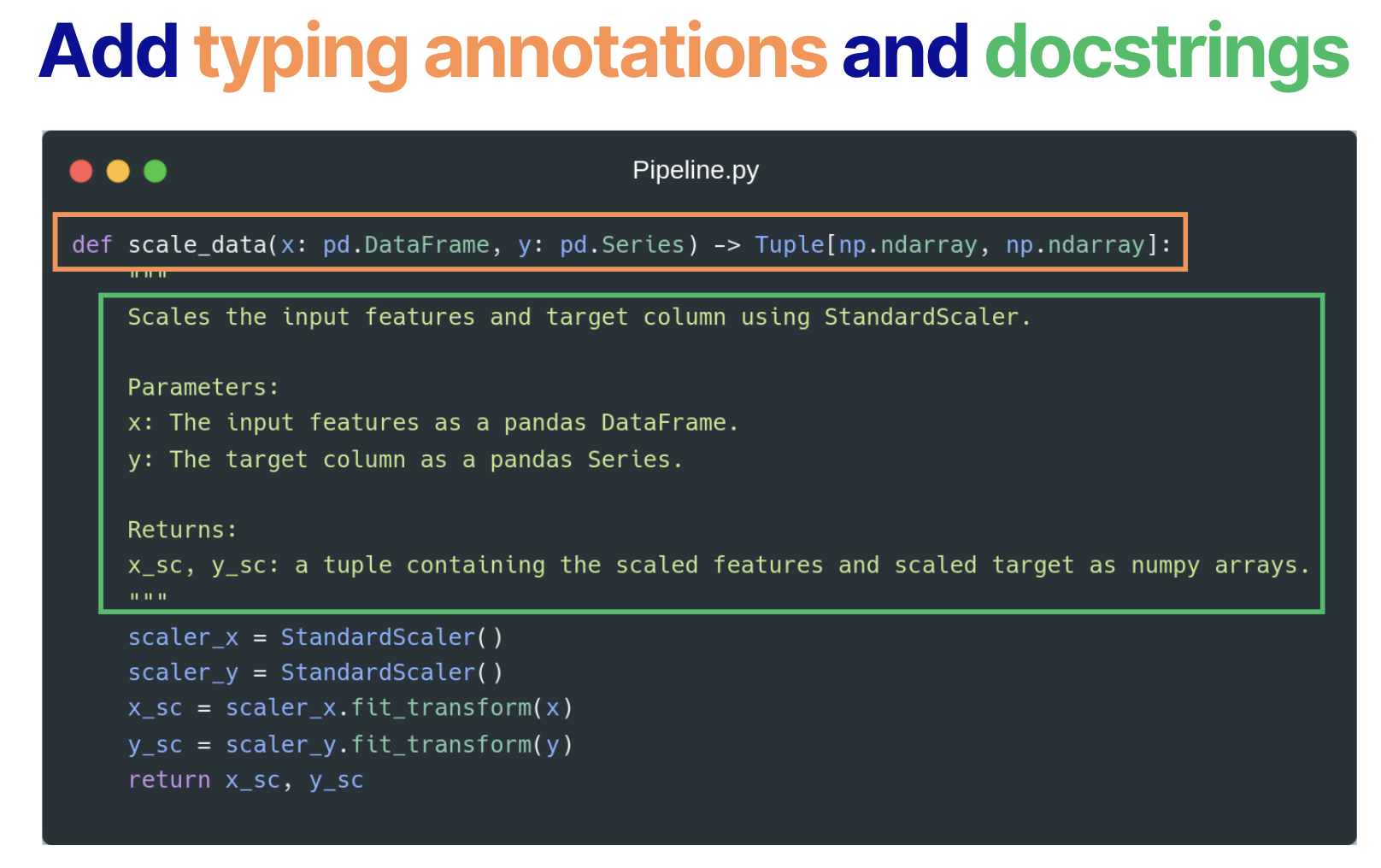
Bad Practice 4: Avoiding Unit & Integration Tests
🟠 Avoiding unit and integration tests leads to:
- Undetected errors in data preprocessing or feature engineering go unnoticed
- Pipeline failures in production
- Unexpected outputs due to untested edge cases
- Difficult debugging
✅ Solution:
- Use unit tests to validate individual components, such as data preprocessing functions or feature engineering steps, ensuring they produce the expected outputs for given inputs.
- Use Integration tests to check how multiple components work together, such as ensuring the model correctly processes preprocessed data or handles edge cases.
Here is an example of the unit test:
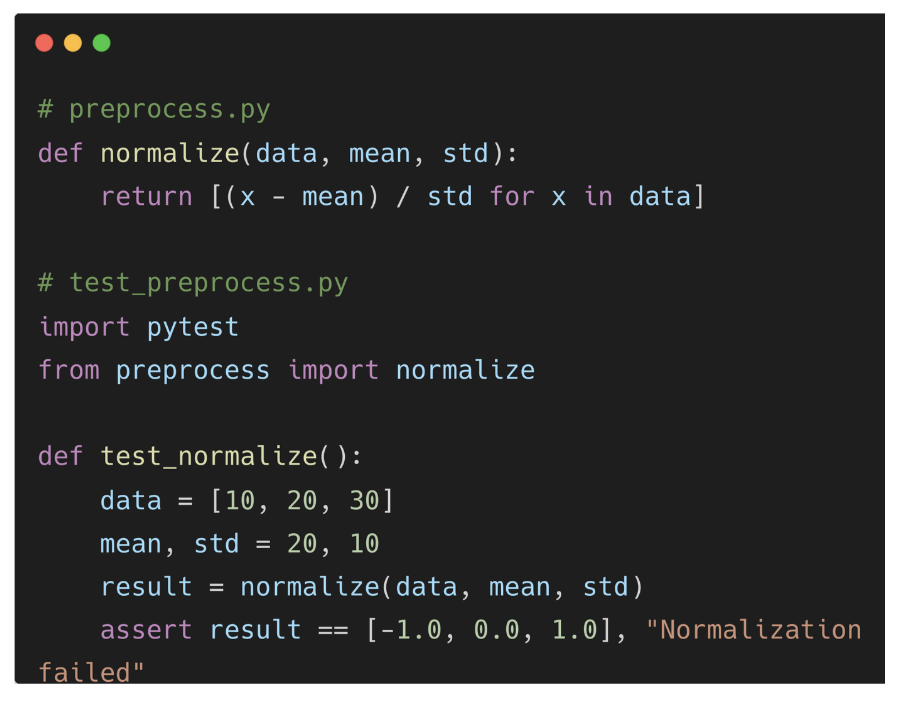
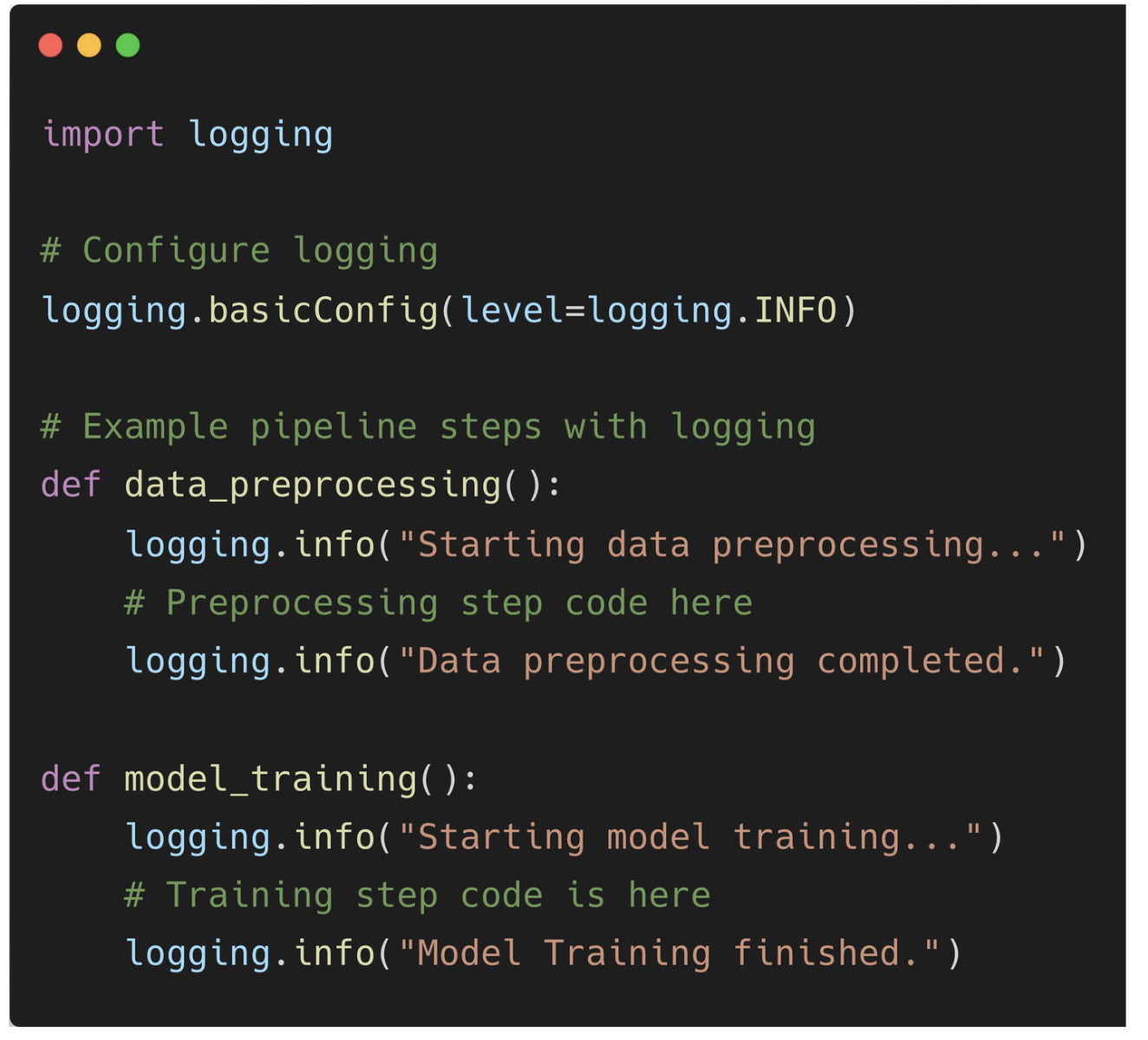
Bad Practice 5: Avoiding Logging
🟠 Neglecting proper logging leads to:
- Difficult debugging: no clear insights into where and why failures occur
- Lack of visibility: hard to track pipeline execution and performance
- Inefficient troubleshooting: more time spent diagnosing errors
✅ Solution:
Use tools like Loguru, Structlog or even simple Python logging to implement logging for visibility into pipeline steps.
Here is an example of logging:
Conclusion
If you want your pipeline to actually work in production, stop hardcoding parameters, modularize your code, add proper documentation, write tests, and use logging.
These aren’t just “nice-to-haves”—they save you from wasting hours fixing broken code and wondering why your model suddenly performs terribly.
Want to read more about ML Pipelines? Check out more of my articles here:
Related Articles:
Subscribe to my newsletter below to receive the articles straight to your inbox!