Gradient Boosting Hyperparameters & Tuning Tips
Mar 15, 2025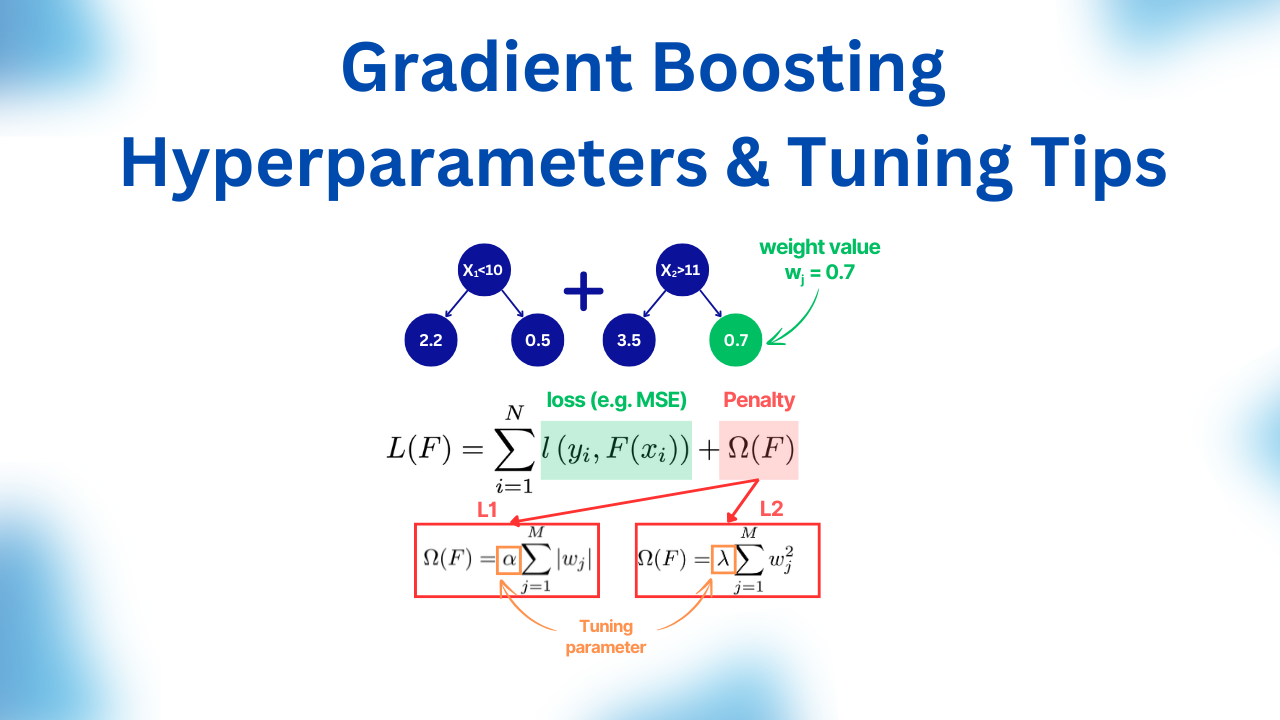
Estimated reading time - 6 minutes
Introduction to Gradient Boosting
Gradient Boosting is a Machine Learning algorithm based ensemble learning approach. In Gradient Boosting, simple models (weak learners) are added sequentially and each learner minimizes the error the previous weak learner made. In most cases, a simple decision tree represents a weak learner.
Gradient Boosting is a powerful algorithm capable to approximate non-linear functions. However, it has many hyperparameters that need to be tuned carefully.
In this article, we dive into the main Gradient Boosting hyperparameters and the practical strategy to tune them.
Gradient Boosting Hyperparameters
1. Learning rate (aka shrinkage, eta)
Learning rate (shrinkage) parameter multiplies the output of each weak learner (tree).
A small value of it literally shrinks each tree output weight values, so smaller values are added to the sum of the tree ensemble.
As such, decreasing this parameter makes the boosting process more conservative because smaller boosting steps are taken.
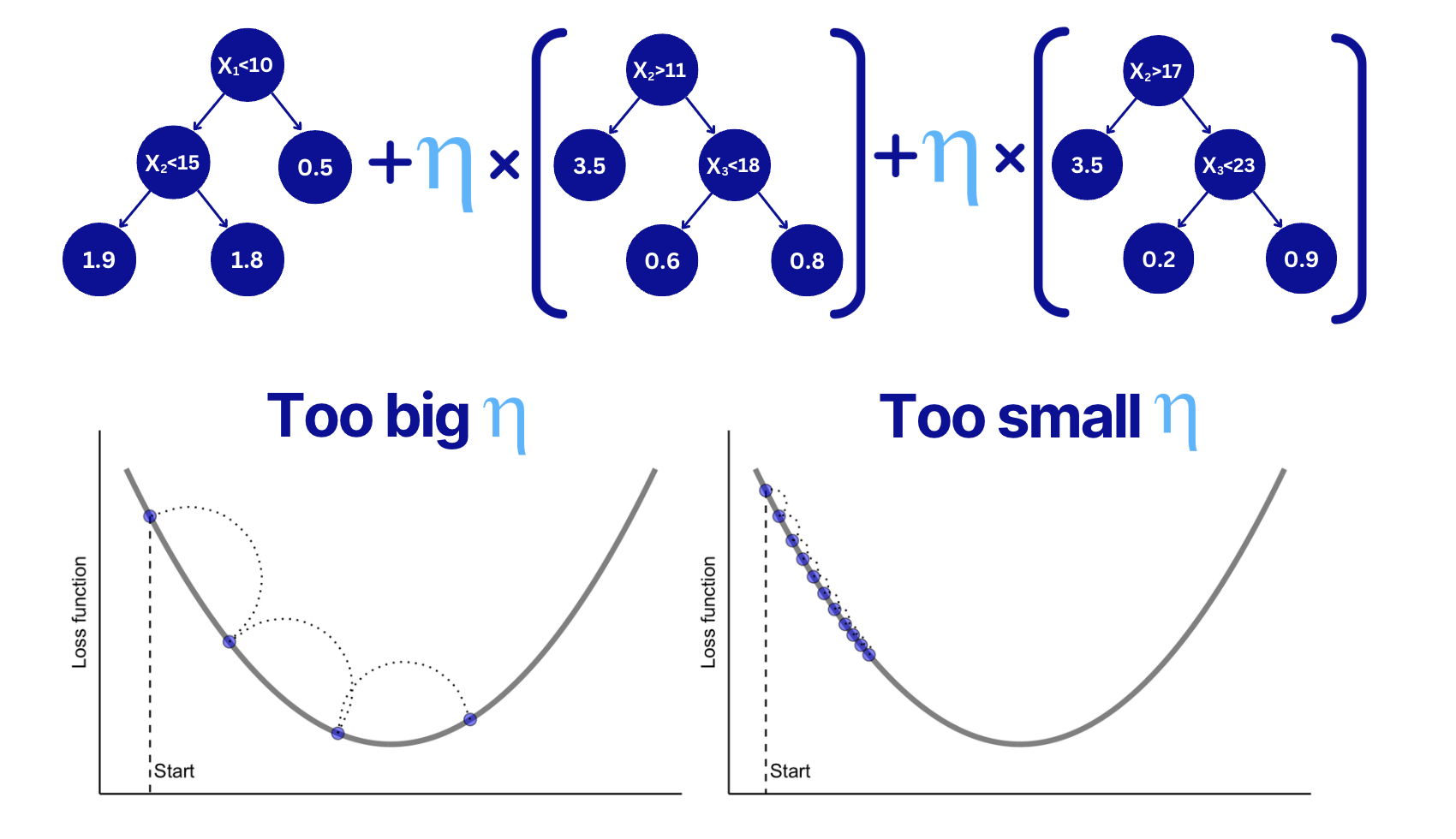
Learning rate influence to Gradient Boosting Tuning
2. Tree depth
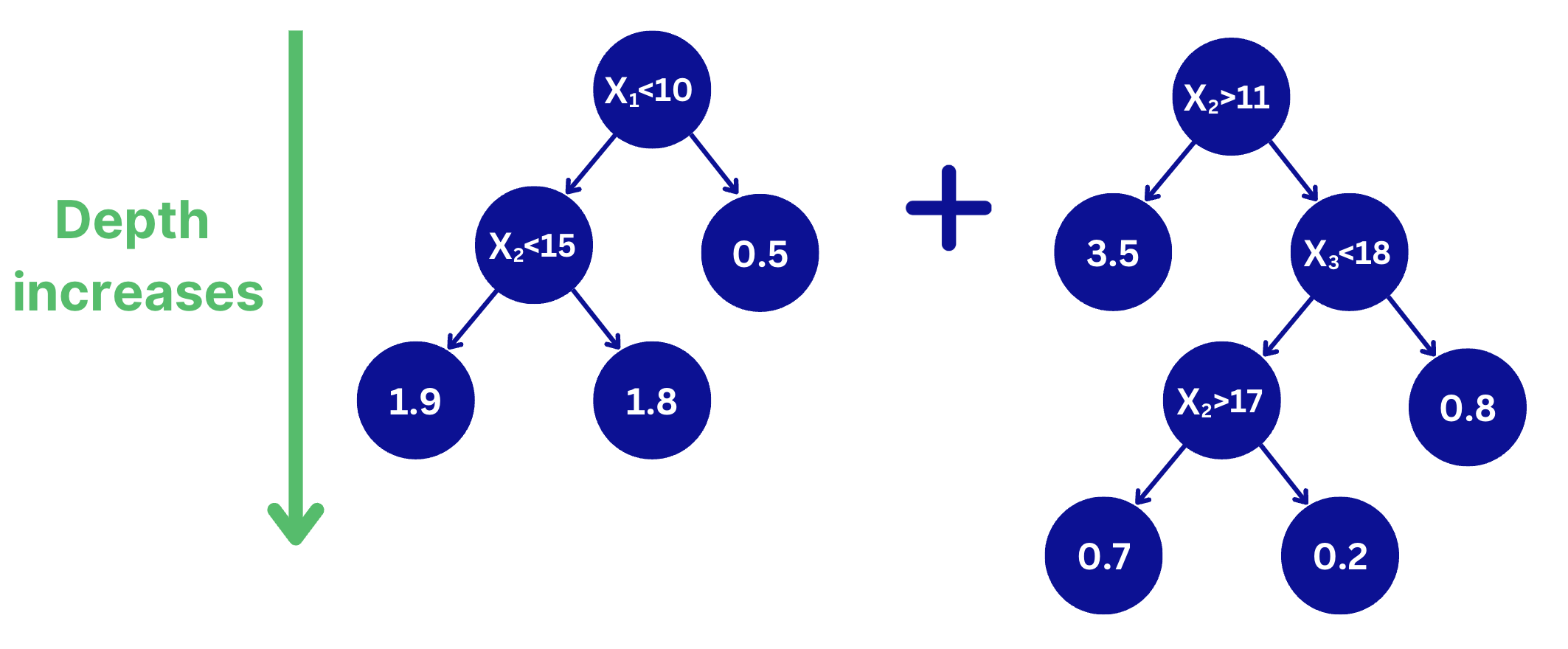
Tree depth defines how deep (complex) the decision trees are. A small tree depth makes the algorithm more conservative and avoid overfitting. However, too small values with combined with a small number of trees can lead to underfitting.
If the depth increases, it makes each tree learn more complex patterns which can result in learning noise. This can quickly lead to overfitting.
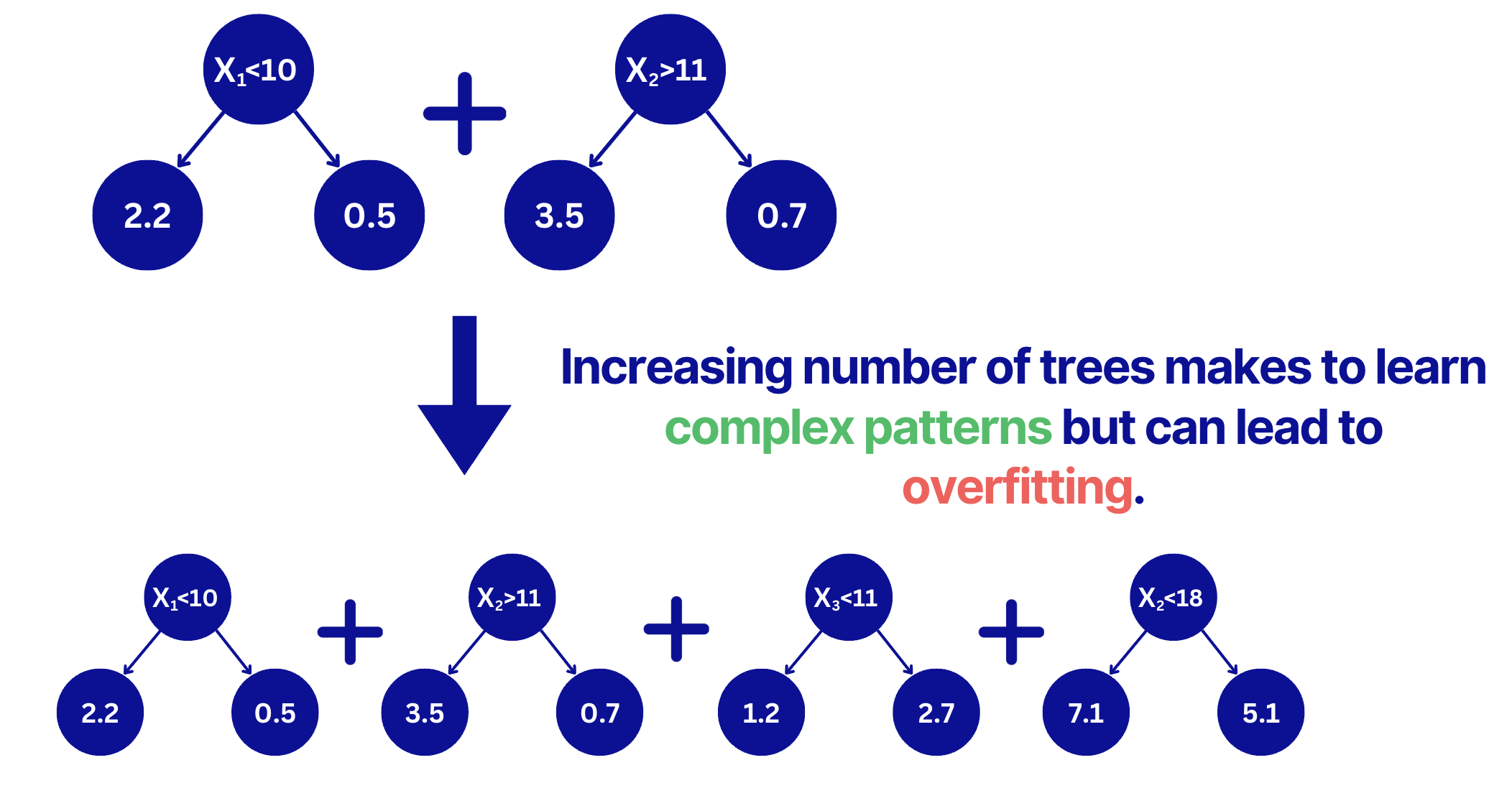
3. Number of trees (with early stopping)
The number of trees will make the algorithm learn more complex patterns (reduce the bias but increase the variance). A big number of trees will drive the algorithm to overfit. A common way to select an optimal number of trees is to use the early stopping technique.
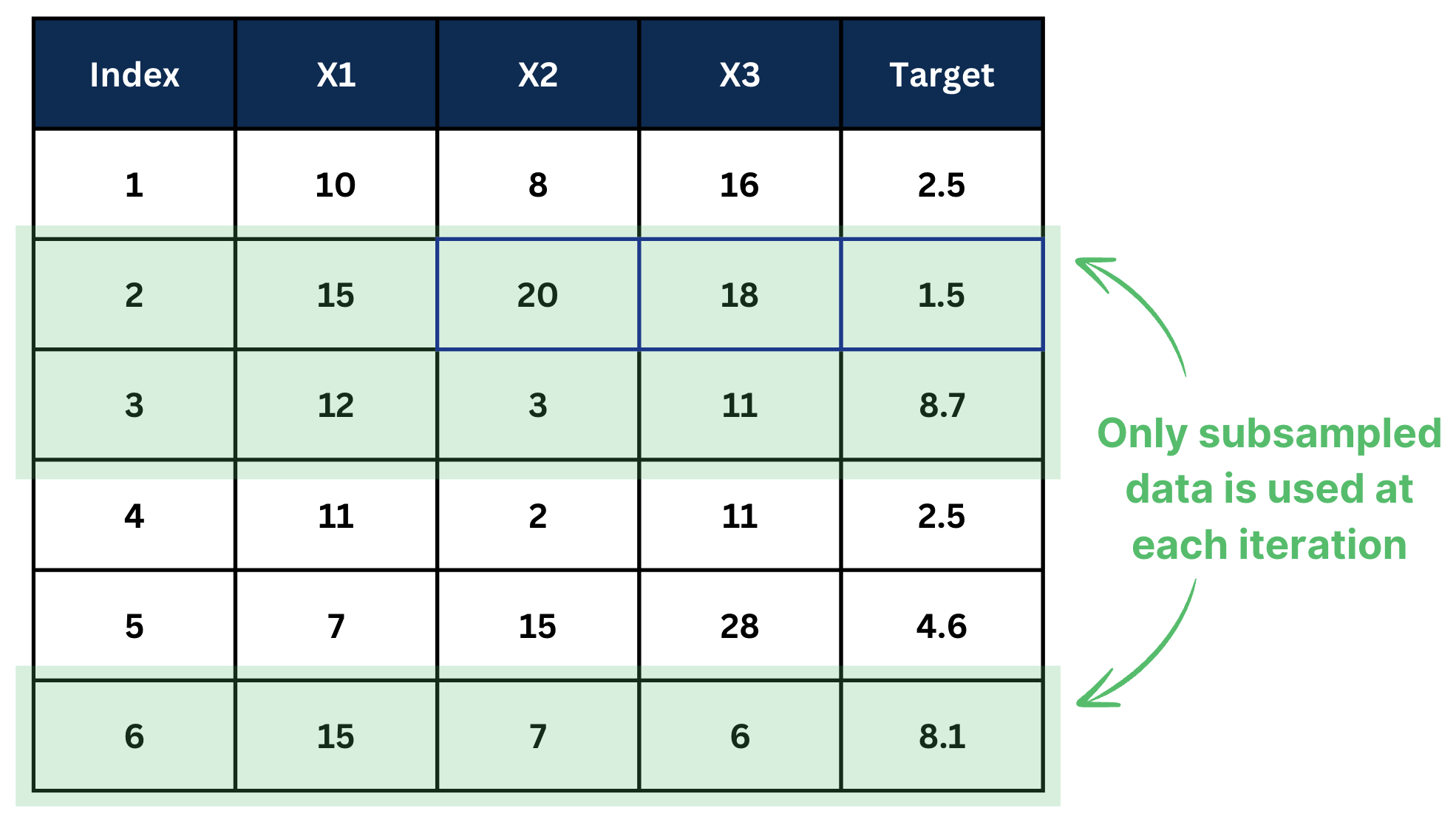
4. Subsample ratio
Subsample ratio defines how much data is used to fit a decision tree at each iteration step.
If subsample ratio=0.5, it means 50% of the data is used to fit a decision tree. Subsampling is performed at each iteration.
Reducing the ratio helps to prevent overfitting because each tree can learn only a part of the information in the data.
It naturally helps to avoid learning complex patterns including noise.
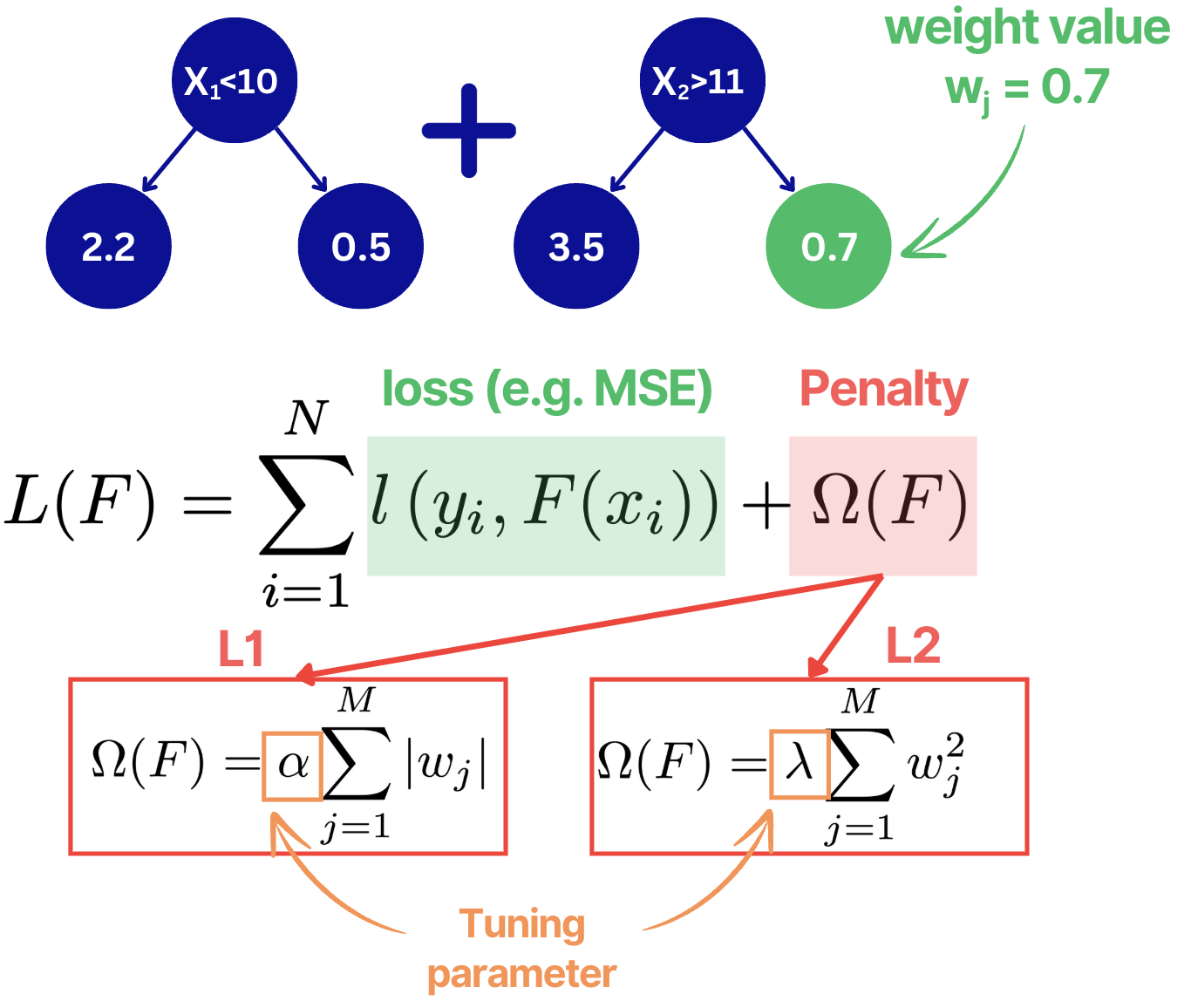
5. L1/L2 regularization
In Gradient Boosting, L1/L2 regularization penalizes weight values that are located at the leaf nodes.
Similar to linear regression, in L1, sum of the absolute leaf weight values are taken while for L2 - sum of squared values.
6. Other hyperparameters
There are other Gradient Boosting hyperparameters such as:
-
Minimum Samples Split (min_samples_split):
The smallest number of samples required to split an internal node. This parameter prevents the algorithm from creating overly specific splits. -
Minimum Samples per Leaf (min_samples_leaf):
The minimum number of samples that must be present in a leaf. Setting this parameter helps smooth the model, ensuring that leaves aren’t too specific. -
Maximum Features (or colsample_bytree/colsample_bylevel):
Instead of using all features for each split, you can limit the number considered. This introduces randomness and can reduce overfitting. - Gamma (or min_split_loss):
The minimum loss reduction needed to make a further split on a leaf node. This acts as a regularization parameter by controlling how “aggressive” a split must be.
In this article, we will learn the practical tips of how to tune Gradient Boosting. In practice, the first 5 listed hyperparameters are enough to tune the algorithm properly, so we will focus on them.
Gradient Boosting Hyperparameter Tuning Tips
Tip 1. Consider inter-relationships between hyperparameters
These parameters are highly related (see the figure below):
- Learning rate (aka shrinkage, eta)
- Tree depth
- Number of trees
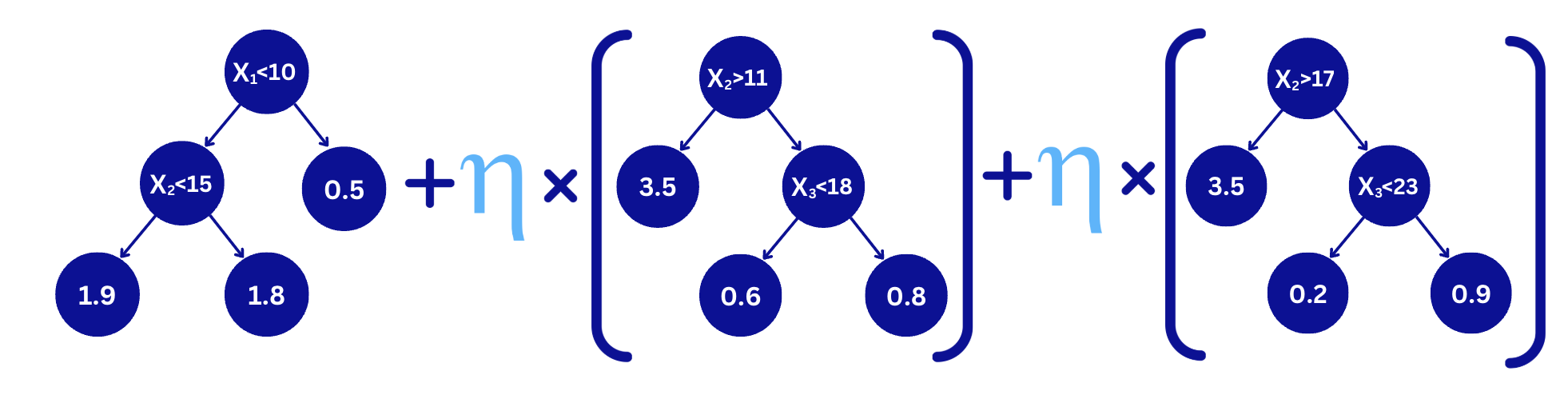
Use this strategy to overcome it:
Step 1:
Fix n_trees high, e.g. 500-1000
Step 2:
Tune the rest of parameters including learning rate and tree depth
Step 3:
For the best set of hyperparameters, tune number of trees using early stopping (15-20 non-increasing iterations)
Tip 2. Use log scale for learning rate range. Don’t make it too low
By exploring values on a logarithmic scale, you ensure that you sample across multiple orders of magnitude, capturing both very fine and broader adjustments.
This strategy helps prevent the search from clustering too narrowly around a suboptimal range, ensuring a more robust and effective hyperparameter tuning process
A good search space would be:
Lower Bound: 0.001
Upper bound: 0.05
Good default value: 0.01
Tip 3. Consider dataset size
For small datasets, using simpler trees with shallower depths—typically in the range of 1 to 3—helps avoid overfitting, as there isn’t enough data to support very deep, complex splits.
Conversely, with larger datasets, deeper trees—ranging from 1 to 6—can be more beneficial because they have more data to learn intricate patterns from, while still maintaining the ability to generalize well.
The takeaway:
For small datasets, use simpler trees - Tree Depth = [1:3]
For big datasets, use deeper trees - Tree Depth = [1:6]
Tip 4. Don’t use L1 AND L2 regularization. One option is sufficient.
Use L2 regularization (reg_lambda):
- As your default choice
- When you expect high feature collinearity but want to keep them all
Use L1 Regularization (reg_alpha):
- When dataset might have irrelevant features and want the algorithm to choose a subset of them
Tip 5: Don’t go too low for subsample size
Setting the subsample size too low can make each tree learn from too little data, leading to unstable predictions and underfitting. On the other hand, using the full dataset for every tree increases the risk of overfitting.
A good search space would be:
Lower Bound: 0.3
Upper bound: 0.7
Good default value: 0.5
Tip 6: Prefer using Bayesian Optimization. Hyperopt or Optuna are your friends.
Tuning Gradient Boosting is not easy because the search space is large (4-5 parameters). In many cases, it can be computationally expensive to run 100s of iterations. Bayesian Optimization increases the chances to converge to a good solution within a relatively small number of iterations.
Good default value: n_iter=100
Tip 7: ALWAYS use k-fold cross-validation.
This is true for all ML algorithms, but ESPECIALLY for Gradient Boosting because of the large hyperparameter space. Your goal is to make sure that hyperparameter selection is stable.
Also, for time series:
- Never shuffle=True
- Only nested (sliding) cross validation
Conclusion
Tuning Gradient Boosting effectively requires a thoughtful approach to hyperparameter selection. By understanding how key parameters like learning rate, tree depth, and subsampling interact, you can balance bias and variance to achieve strong model performance. The proposed tips have been tested over a wide range of problems and should be a good starting point.
If you want to dig deeper into Gradient Boosting, here is the article on the Gradient Boosting Learning Roadmap.
To stay up to day with my articles both on the technical and career part of your ML journey, subscribe to my weekly newsletter below!